
Step by Step Pathway to Implement Machine Learning Projects
Artificially providing the ability to possess the intelligence to our computers is known as artificial intelligence. Machine intelligence or Artificial intelligence, in a broader sense, tries to mimic the intelligence of human beings and sometimes performs even better than humans after completing the learning stage.
One fantastic example of machines surpassing human intelligence is analyzing a more significant chunk of data. Suppose some human is studying a larger piece of data, and while doing so, they observe 500 similar samples. They might probably become biased and skip going through every sample after that, which can be wrong sometimes. But on the other hand, machines will analyze every sample thoroughly and provide insight, which will be less erroneous.
Key takeaways from this blog
After going through this blog, we will be able to understand the following things:
- Understanding the exact pathway while solving any problem statement using machine learning technology.
- How do we categorize available data into three crucial training, validation, and testing datasets?
- What are the different use cases of training, validation, and testing datasets?
- How do we make Machine Learning models production-ready and roll out them to the world?
- What are the categories of Machine Learning based on the use cases?
So let's start without any further delay.
Types of Machine Learning use-cases
In the current era of software engineers, we mainly have traditional Information Technology (IT) infrastructure where business teams (or experts) make decisions and convey them to our developers. Developers write logic as programs and integrate it with the IT system, producing output in the form of decisions. At the current stage of development, ML techniques can not replace this entire process yet can complement them for betterment. And for this betterment, there can be two scenarios,
What is Decision Supportive use case of ML?
In this case, IT experts define rules based on their experience. Our Machine Learning models analyze the data and provide their insights, which can support the rules made by experts or even discard them.
For example, in our traditional banking systems, bank experts make rules that if a farmer has not repaid the previous loan on time, do not grant them another loan as there is a higher chance that he will not repay it. But our machine learning model analyzed that farmer's previous loan repayment history and analyzed that if that farmer takes the loan in the spring season, he repays it very soon because he makes a more significant profit from spring crops. In such a scenario, the ML model will help our bank experts to rectify their decisions.

Other possible examples:
- Prediction of the attrition rate for any company.
- Predicting the fraudulent transactions via credit/debit cards.
- If you can also think of an example, please send them to us using the feedback section in the last.
What is Cognitive use case of ML?
IT experts can not define explicit rules for some tasks in this case. Our ML algorithms try to mimic the cognitive intelligence possessed by humans.
For example, a bank manager is reading a customer's mail and is trying to identify whether his customer is happy with the banking services or not. He made the rule that if the content of mail includes "fantastic" word, it means the customer is satisfied. Suppose in the mail, the customer writes,
The banking services are so fantastic that every issue gets solved within 3 to 4 years.
Although the mail includes words like "fantastic" and "issues are getting solved", the bank manager can identify sarcasm, and the customer is unhappy. Sowe can not explain this intelligence in hard-coded rules. Here machines try to learn humans' cognitive intelligence.

Other possible examples:
- Understanding the speech signals.
- Image recognition
- If you can also think of an example, please send them to us using the feedback section in the last.
If we have noticed clearly, we see that the decision-supportive use cases are generally structured data with rules defined in the numerical format. But on the other hand, in cognitive use cases, we have data, not in numbers but in images, videos, or text format. Computers understand the numbers, and we need to convert these data samples into a computer-readable format.
Life Cycle of Any Machine Learning Project
In computer science, specifically in the IT sector, business and technology need a high level of coordination. The difference between "business demand" and "feasibility of demand via technology" is known as the IT error. The more the coordination between business experts and coders, the lesser will be the IT error.
In Machine Learning solutions, we need to have the most coordination between technology and business verticals. In the case of decision-supportive use case, this tech requires rules formulated by business experts and the corresponding data to support or derive new rules. And in the case of cognitive use-case, a close watch on the learning process is required as humans have to evaluate the model's accuracy.
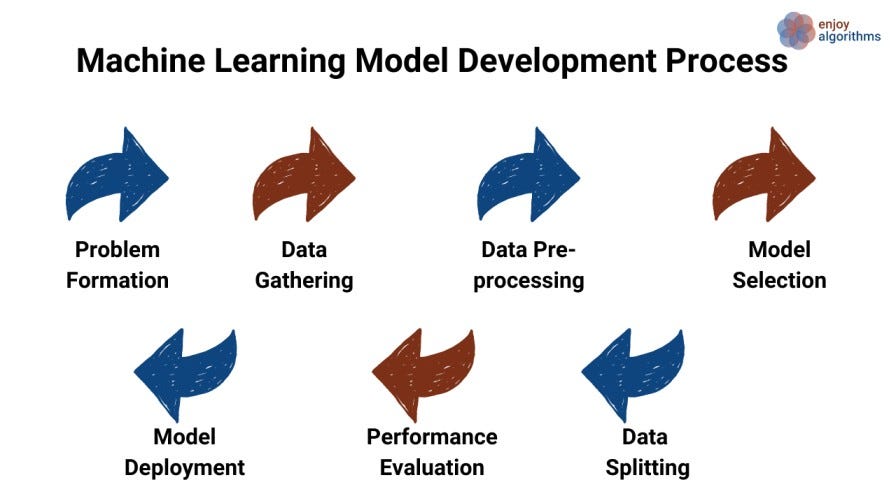
For any Machine Learning project from business experts, there are mainly seven different verticals or phases it has to pass. All of these seven verticals are mentioned in the image above. Let's discuss them one by one.
Problem Formation
We might have heard that half the problem is solved if the problem is identified clearly. Technology is developed to solve a particular problem, but this process requires a "clear definition" of the problem we want to solve. It is more like goal finalization.
For example, suppose we are the head of any banking firm and want our customers to be happy. Till now, we roughly stated the central objective, but this can not be a problem statement that technology would target. Machine learning techniques would provide several solutions to enhance the customer experience in multiple ways. One could be alerting the customers in case of fraudulent transactions.
Now we have a clear problem statement in our mind, we can start thinking from the requirement perspective. We want to solve the defined problem statement using the machine learning technique, and the core requirement for this technique is historical data. So let's see our next stage of Data Gathering.
Data Gathering
There can be three scenarios,
- Case1: Sufficient data is available with all the essential attributes.
In this case, we can start utilizing the available data and find whether it is present in the supervised, unsupervised, or semi-supervised format. Based on this, we will begin analyzing the dataset further.
- Case 2: Sufficient data is available but lacks essential attributes.
In the second case, we need to analyze the data and check whether available attributes are sufficient to make the model or not. This stage requires a trial and error condition. We can start categorizing the data and check whether ML techniques can fulfill our objective. If not, we will have to capture a sufficient amount of data from scratch.
- Case 3: Either insufficient data or no data is available.
In such a scenario, we will have to gather or record the data from the start. We might need some domain knowledge about the problem statement or can consult some experts. For example, suppose we are trying to sense whether any transaction is fraudulent. What attributes( previous month's transaction history, type of shopping, etc.) would be essential to learn the mapping function successfully?
Note: There are multiple platforms like Kaggle or government data portals where we can easily find datasets for our academic purpose.
Once we collect the dataset, we need to process it. We can not expect our data to be accurate as multiple dependencies exist. So let's process them to make them usable to us.
Data Pre-processing and Analyzing
After collecting the data, it presents in the raw format and can not be used directly in the model-building process. We need to pass this raw data through a "set of defined processes", known as data pre-processing steps. These steps vary based on the project requirements and raw data quality. Some famous data pre-processing steps for structured data are,
- Feature selection
- Feature engineering
- Handling missing data samples,
- Reducing dimensionality, etc.
After this step, we should have rich and machine-readable format data. For unstructured data, like text, images, and videos, our computers need different processing steps to make it understandable to our systems. We also have covered the text data pre-processing in our blog.
After this step, we have the machine-readable data, and we can start using machine learning algorithms to learn the dependencies.
Model Selection
There are many algorithms in the market; which algorithm should we target? Selection of model mainly depends upon these factors,
- Nature of Input data: Whether the data is in supervised, unsupervised, or semi-supervised format.
- Nature of problem statement: Whether we have to solve the classification problem, regression problem, clustering, or dimensionality reduction.
- Need for explainability: Statistical and famous machine learning models like SVM, Linear regression, logistic regression, decision trees, etc., possess an explainable nature. Explainable can be described as "what business demands," and "how ML models are achieving it" should be traceable. Neural Networks and Deep Learning models lack explainable properties.
- Availability of computational capability: Computational power can force us to choose the lesser complex model by compromising accuracy. Linear and logistic regression algorithms require very little computing power.
- Availability of data samples: Algorithms like SVM can work with fewer data samples, while Neural Networks and Deep Learning demand more data samples.
- Decision Supportive or cognitive use case: Statistical models like linear regression and other ML algorithms can work perfectly in the decision-supportive use case. But in the case of cognitive use-case, to achieve substantial accuracy, Deep Learning algorithms are required.
Once the model is finalized, we need various sets to check whether our selection is good or not. Let's discuss how to do this data splitting.
Data Splitting
We have decided on the algorithm we need to train; we need to make three sets from the processed data: training, validation, and test datasets. Let's first learn about all these three datasets.
- Training Data: This dataset is responsible for training our model. It is generally 60–80% of the processed data we have.
- Validation Data: Once the model gets trained, we check the model's performance on our validation set to check whether the minima is reached for the cost function. If not, we tune various hyperparameters and train our model on the training dataset again. It is generally 10–20% of the processed data.
In the image below, if we consider the initial choice values of parameters as a hyperparameter, we need to check multiple times for which initialization the cost is the minimum.

- Test Data: It is generally 10–20% of the processed data. Once the model starts performing better on the validation set, we test our final model on completely unseen (but processed) data to check whether our model-building process becomes successful or not. If yes, we can move ahead with the performance evaluation step to test the developed model on various parameters. If not, we need to debug the reason or select a different algorithm.
In some of the online solutions, we might find no validation or testing data. People generally get confused about these two datasets' use cases, making it one of the most asked basic questions in ML interviews. While training a Machine Learning model, we use a validation dataset to tune the parameters. So we can say that not directly, but our model knows which set of hyperparameters will achieve better results on the validation dataset. On the other hand, test data is unseen data used when the model development phase is completed.
But how do we split the data?
There can be mainly three ways of doing so,
- Splitting randomly into three buckets
- Splitting the data such that all three sets contain all possible variations in the dataset. This splitting is considered to be the best split.
- Multiple random splitting was performed, and checked which combination was working better. It is a hacky way to showcase the best results for your research work.

Once we have made the final model, we need to evaluate it on several metrics. Let's understand them.
Performance Evaluation
Once our model is ready, we must evaluate it rigorously on different metrics and check whether it beats previous methodologies. The evaluation metrics can vary based on project requirements.
- Classification model evaluation metrics: Accuracy, confusion matrix, F1 score, Area under the curve, etc.
- Regression model evaluation metrics: Mean Absolute Error, Mean Squared Error, R-Squared, etc.
We sometimes need to design our evaluation metric, but that is beyond the scope of this blog to discuss here. If our model performs as per the expectations, there comes a phase to roll out to the world.
Rollout of Model
Once our model clears our evaluation criteria, we integrate it with our mobile apps and website APIs. It will start giving predictions on the user data in real time. But there can be several scenarios based on which we might need to retrain our ML algorithms. Some of these scenarios are:
- Data drift: Our model worked on the collected dataset perfectly, but the data trend has changed a lot which was not present in the raw data we collected earlier. For example, we made our model predict the stock price based on the historical information of the last five months. But we observed that the stock market trend completely changed over the previous five days. In such a case, the model must re-learn these things, which requires retraining the model.
- New datasets: We figured out we were not recording one attribute earlier, which proved beneficial. Then we must include that attribute to enhance the accuracy of our model. Here we would need retraining of the model with newer features.
- Learning from mistakes: There can be situations like, for a particular word, we marked our email as spam, but then we realized it was incorrect. But we made our raw data with earlier assumptions, and the model also learned the same thing. We need to rectify those mistakes and retrain the model to perform better.
There can be more reasons, and as we discussed, this technology demands close coordination with business so that retraining can solve the problem whenever new things are needed.
Conclusion
In this article, we have learned about the different use cases of Machine Learning technology. We also discussed the complete pathway, including problem formulation, data gathering, pre-processing, model selection, data splitting, model building, performance evaluation, and finally, the model rollout. These steps need to be followed while building any Machine Learning project. We hope you enjoyed it.
Enjoy Learning! Enjoy Algorithms!
Share Your Insights
More from EnjoyAlgorithms
Self-paced Courses and Blogs
Coding Interview
OOP Concepts
Our Newsletter
Subscribe to get well designed content on data structure and algorithms, machine learning, system design, object orientd programming and math.
©2023 Code Algorithms Pvt. Ltd.
All rights reserved.