
machine-learning-concepts
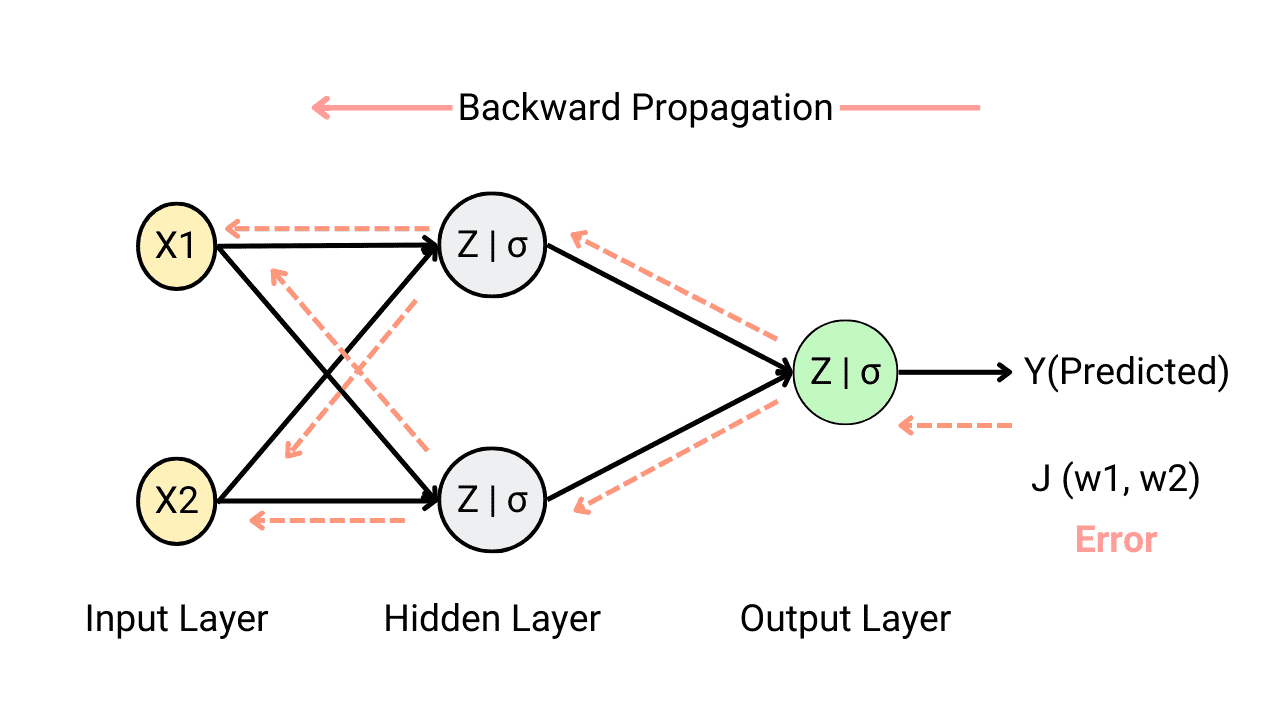
What is backpropagation in neural networks and why do we need it?
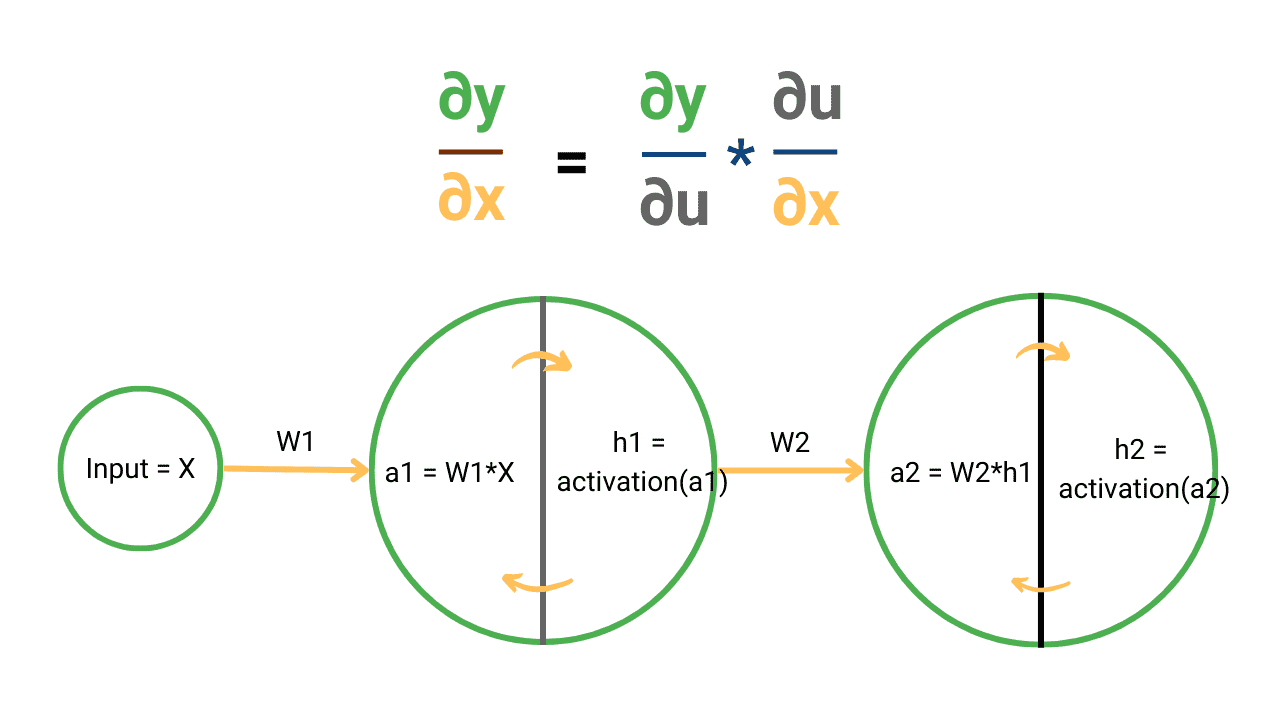
Calculus Chain Rule for Neural Networks and Deep Learning
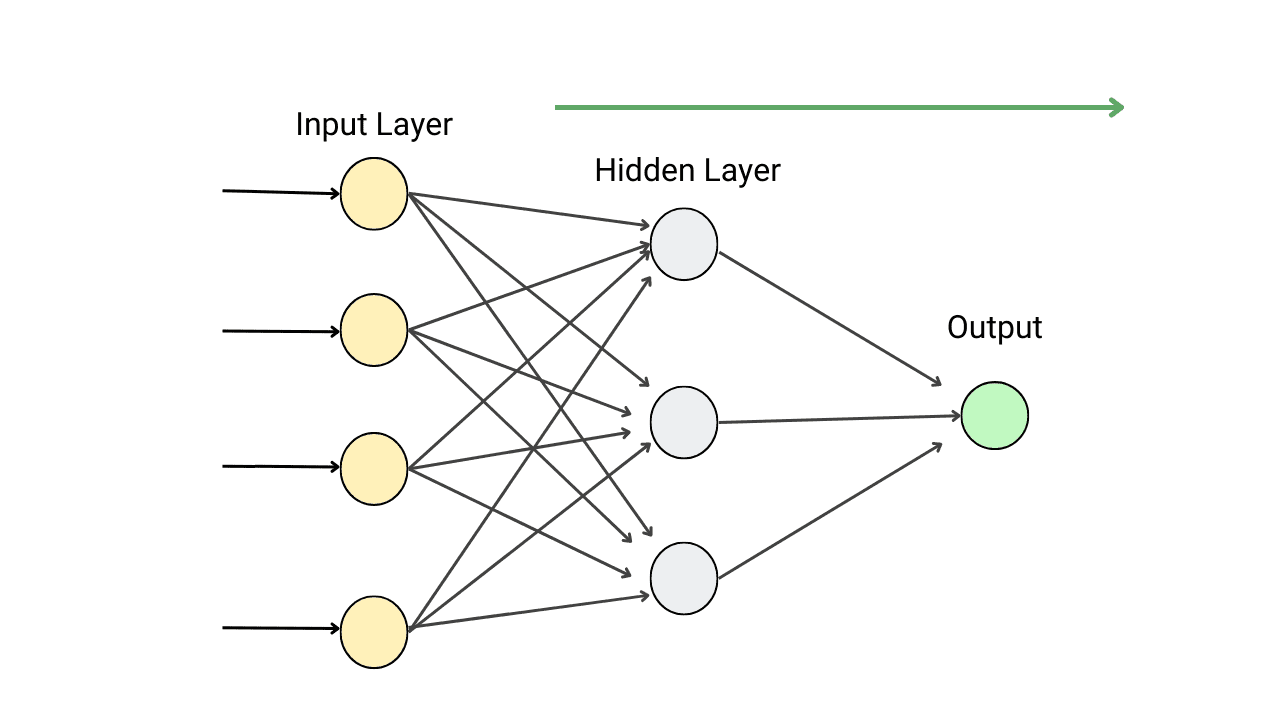
How Forward Propagation Works in Neural Networks?
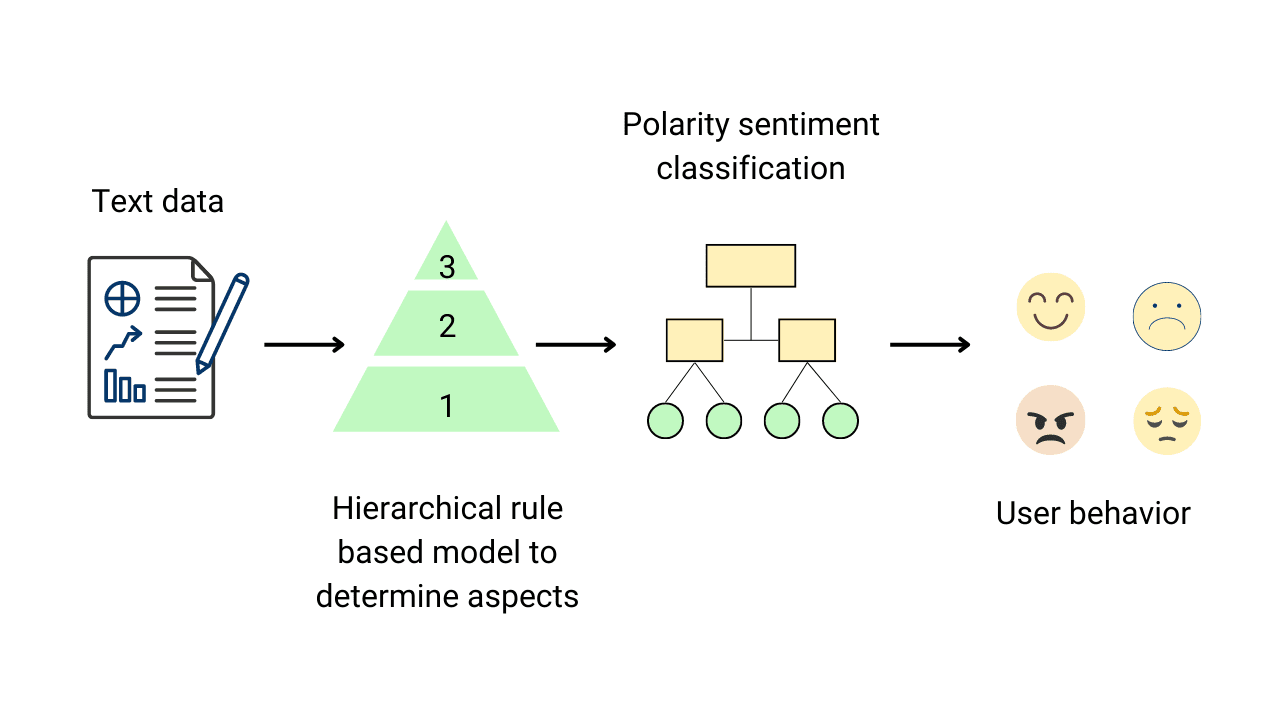
Aspect Based Sentiment Analysis (ABSA) in Python
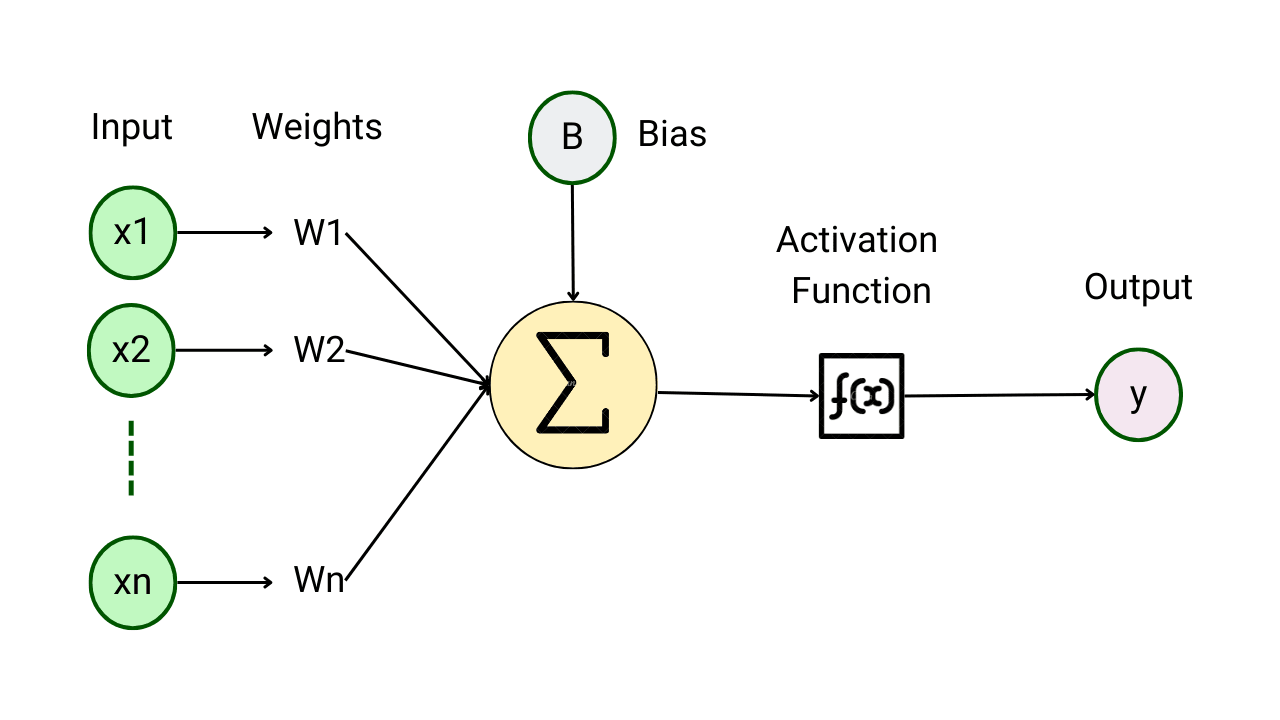
Introduction to Activation Functions in Neural Networks
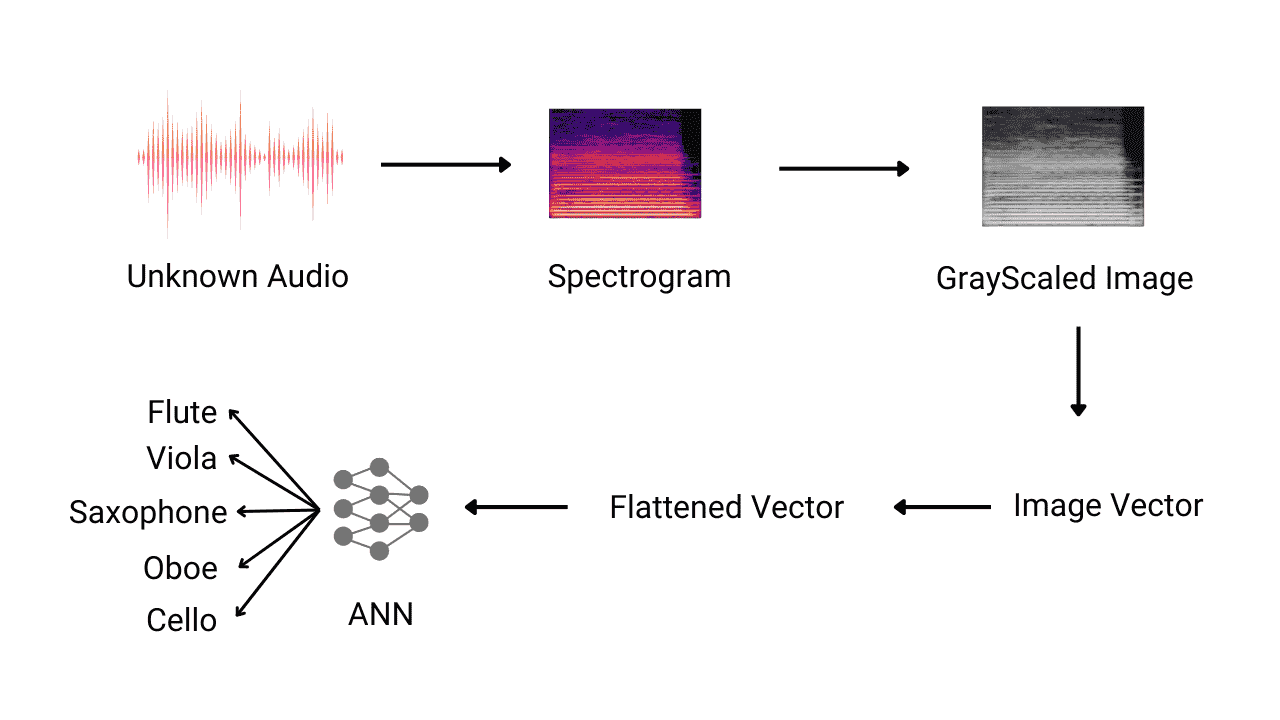
Detection of Music Instrument using Neural Networks
©2023 Code Algorithms Pvt. Ltd.
All rights reserved.