Courses
Courses
Blogs
Blogs
Tags
Reviews
Stories
Contact Us
EnjoyMathematics
machine-learning-interview
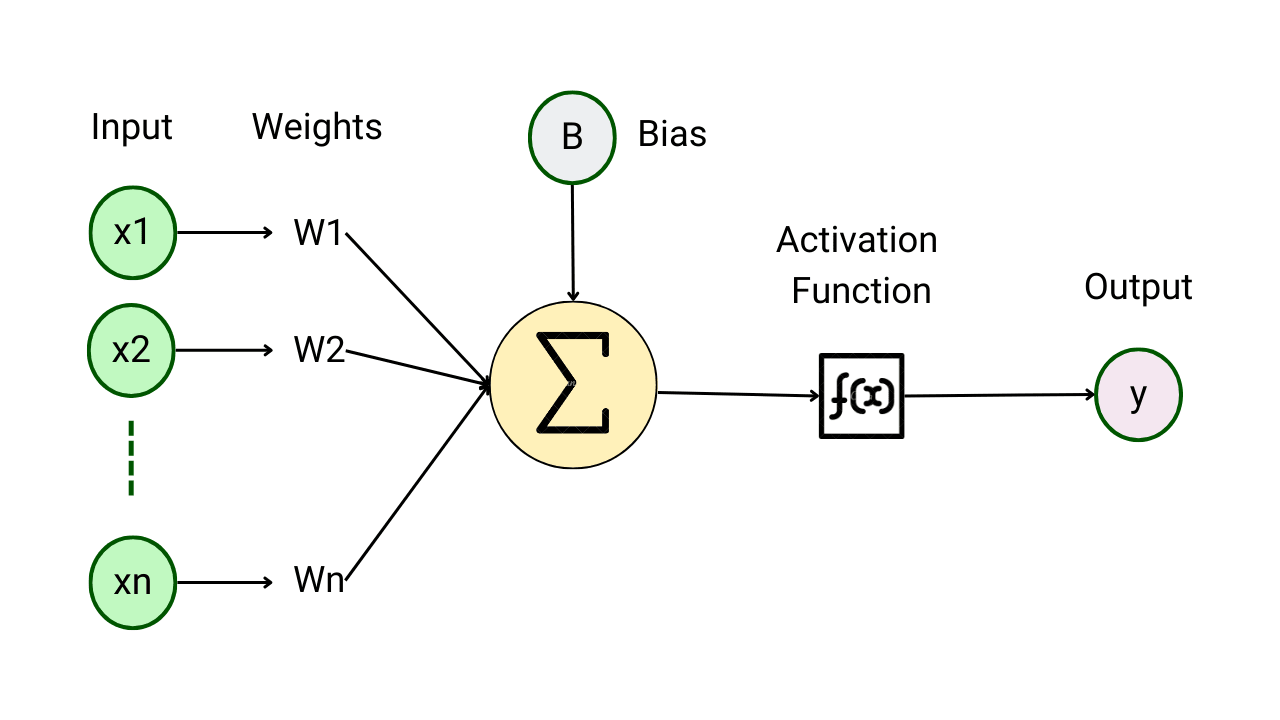
Introduction to Activation Functions in Neural Networks
18 June 2023
Different Types of Machine Learning Models
08 February 2023
Gradient Descent Algorithm in Machine Learning
08 February 2023
KNN Algorithm in Machine Learning
01 January 2023
Feature Selection Techniques in ML
01 January 2023
Regularization in Machine Learning
12 December 2022
Load More Blogs
Find us on:
Linkedin
Medium
Facebook
Twitter
Courses
Latest Blogs
Shubham Blogs
Ravish Blogs
Popular Tags
EnjoyMathematics
About Us
Contact Us
Terms and Conditions
Refund Policy
Privacy Policy
Cookie Policy
©2023 Code Algorithms Pvt. Ltd.
All rights reserved.