Courses
Courses
Blogs
Blogs
Tags
Reviews
Stories
Contact Us
EnjoyMathematics
data-structures
Level Order Traversal (BFS Traversal) of Binary Tree
15 August 2024
Real-life Applications of Stack Data Structure
15 August 2024
Iterative Preorder, Inorder and Postorder Traversal Using Stack
15 August 2024
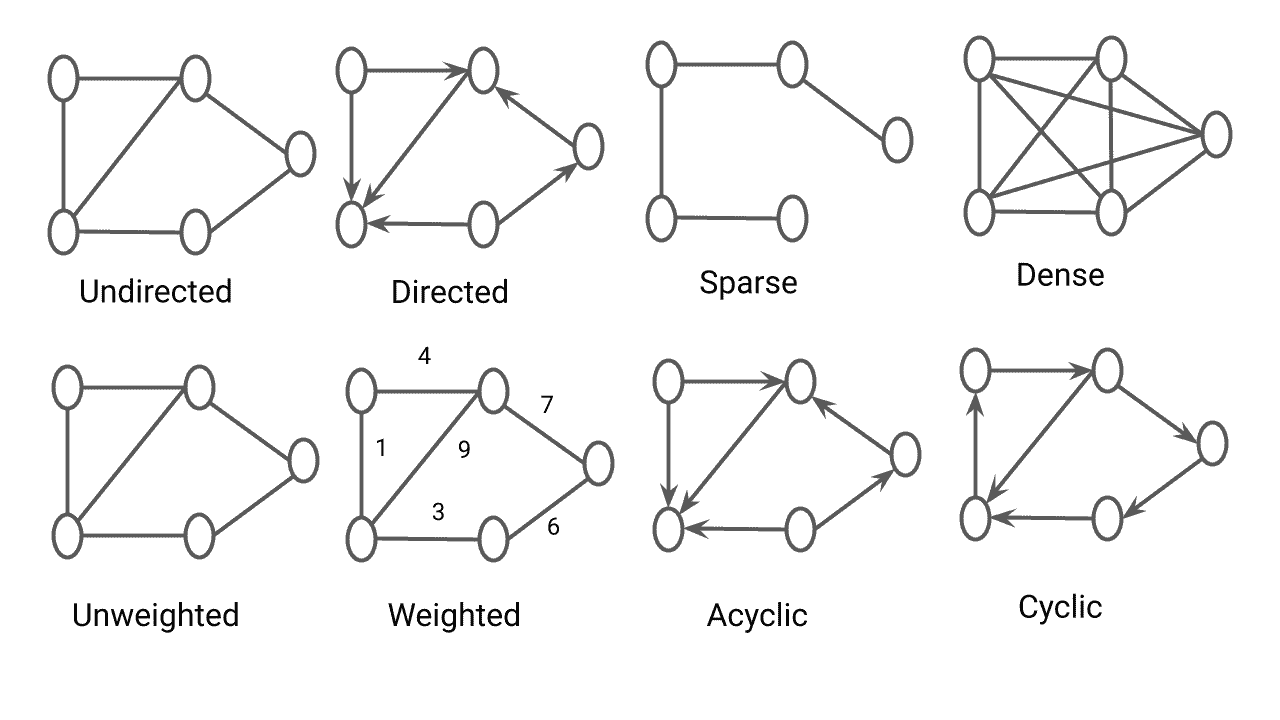
Types of Graph in Data Structures
06 November 2023
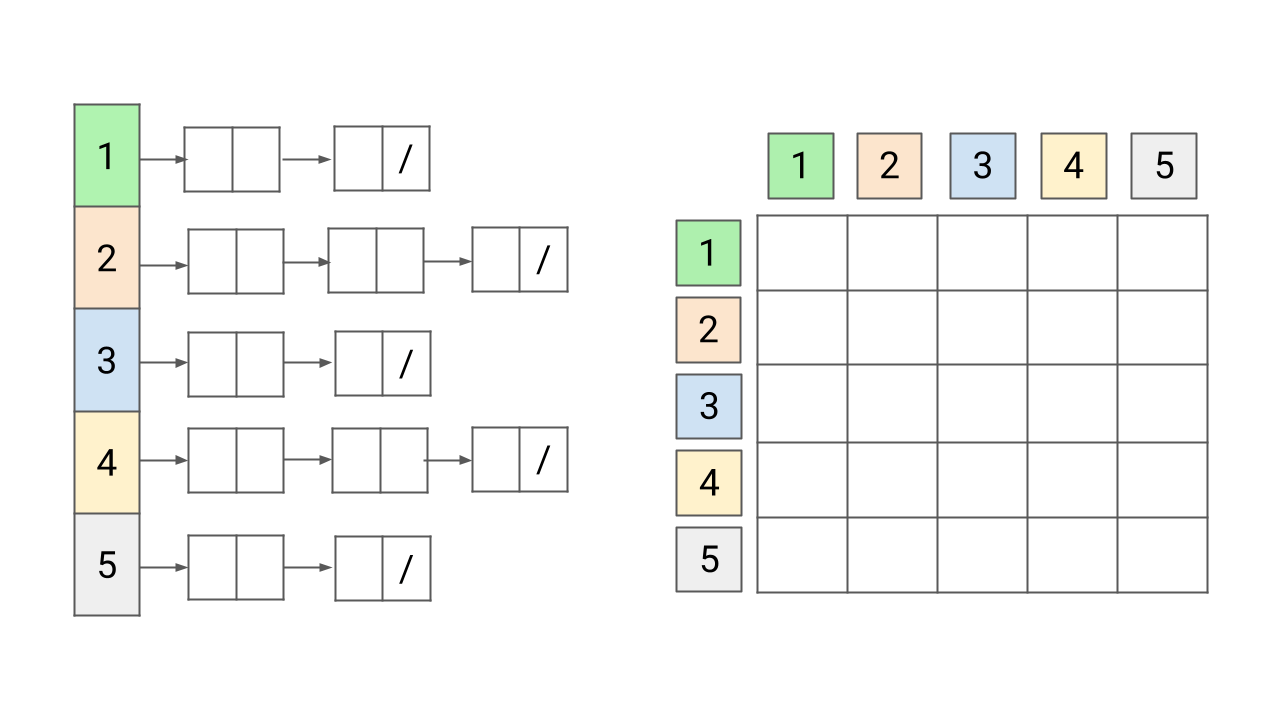
Representation of Graph in Data Structures
06 November 2023
Dynamic Array Data Structure in Programming
26 August 2023
Load More Blogs
Find us on:
Linkedin
Medium
Facebook
Twitter
Courses
Latest Blogs
Shubham Blogs
Ravish Blogs
Popular Tags
EnjoyMathematics
About Us
Contact Us
Terms and Conditions
Refund Policy
Privacy Policy
Cookie Policy
©2023 Code Algorithms Pvt. Ltd.
All rights reserved.