
machine-learning-projects
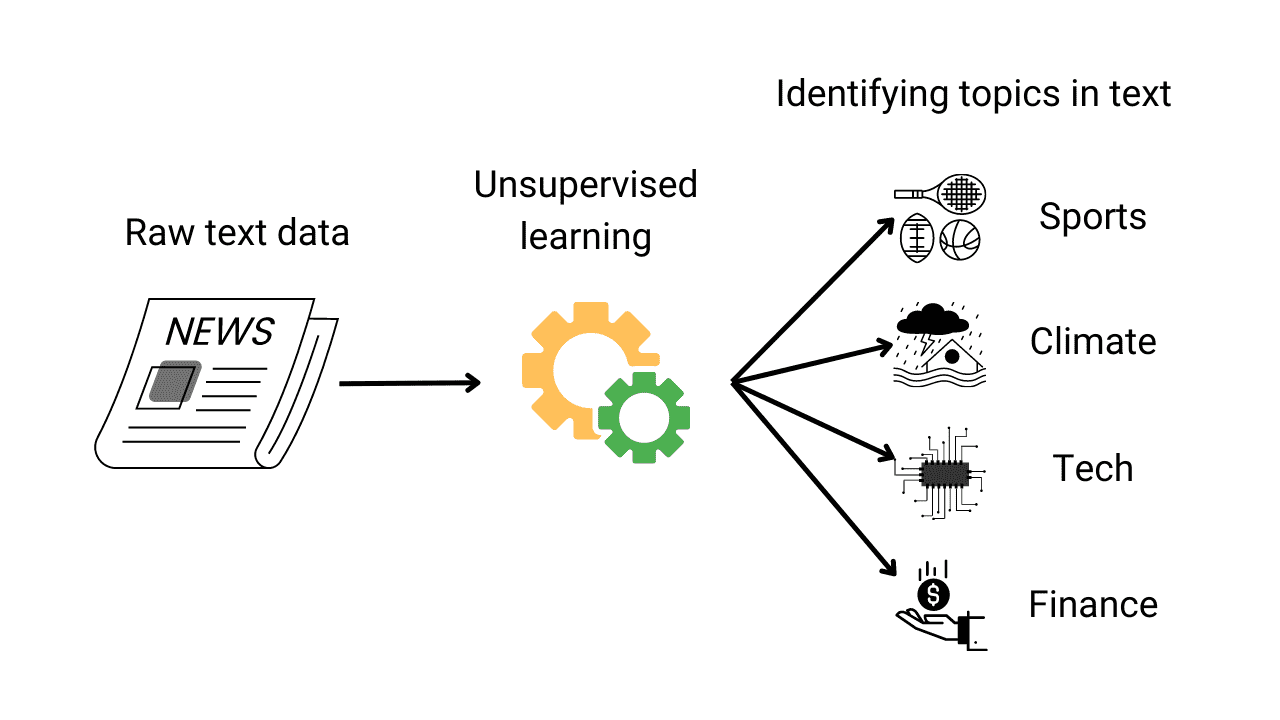
Topic Modelling using LDA and LSA with Python Implementation
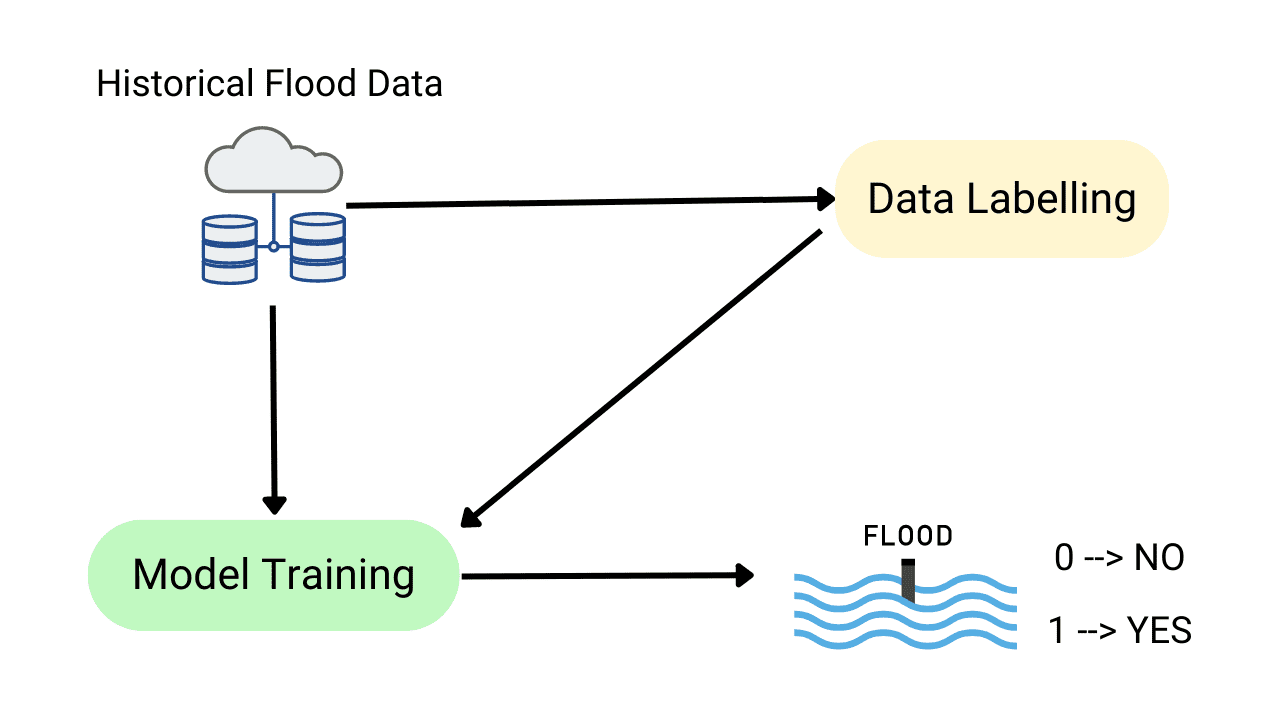
Flood Prediction using Machine Learning Models
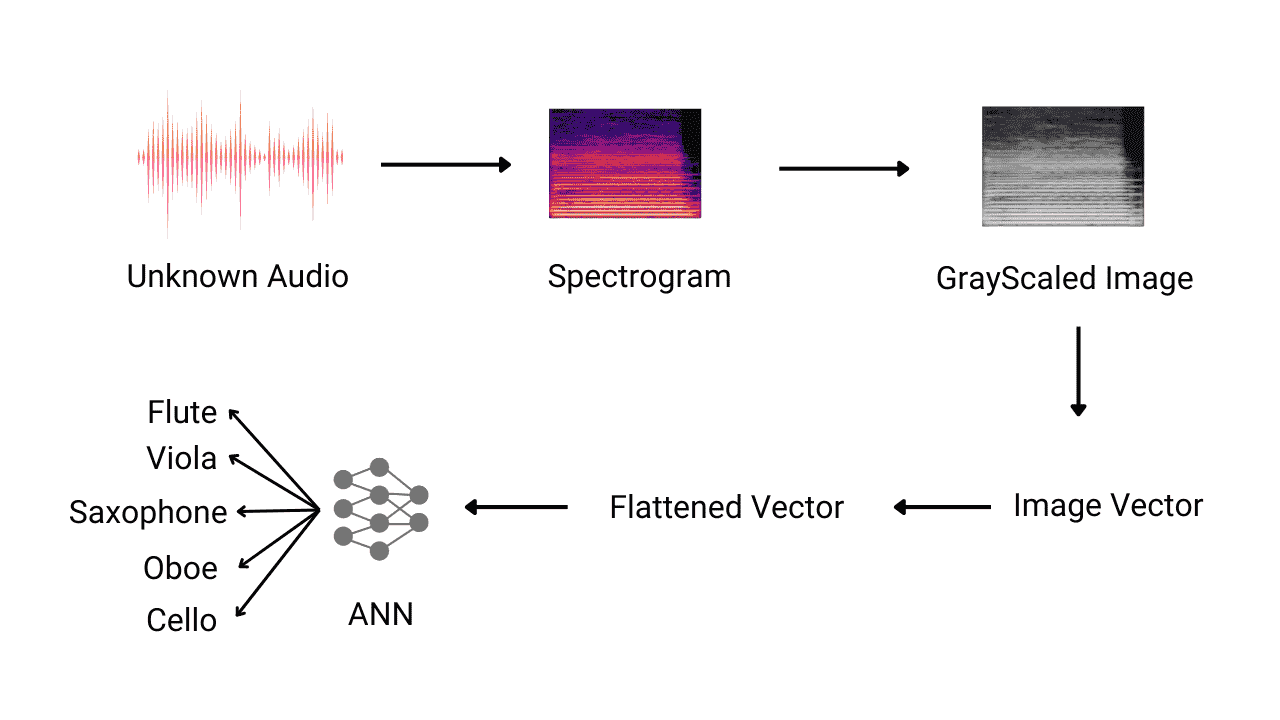
Detection of Music Instrument using Neural Networks
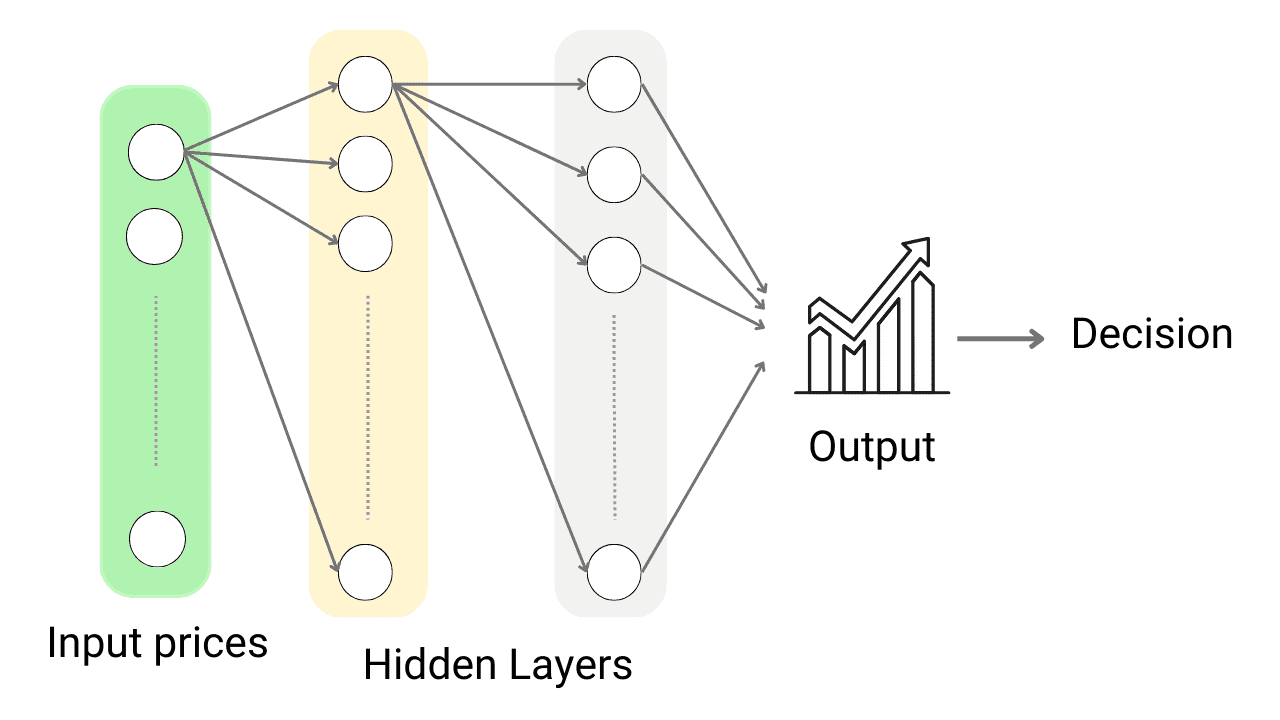
Stock Market Price Prediction Using Machine Learning
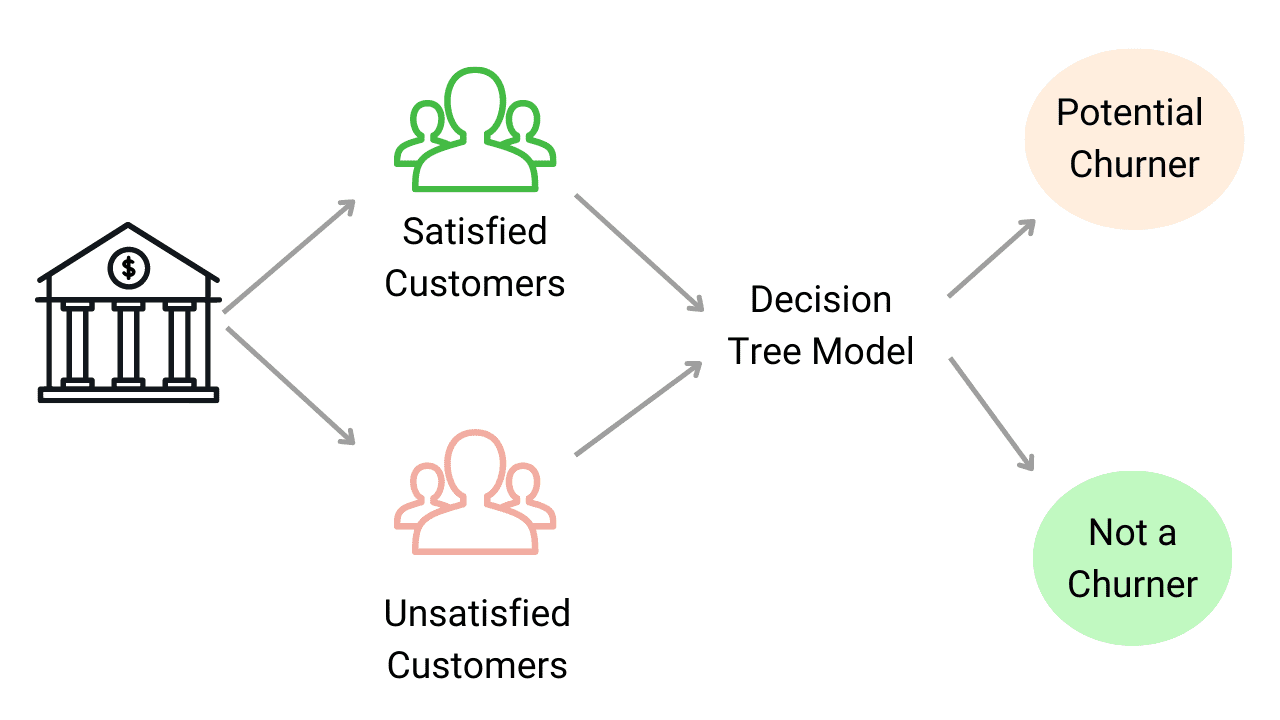
Customer Churn Prediction using Machine Learning
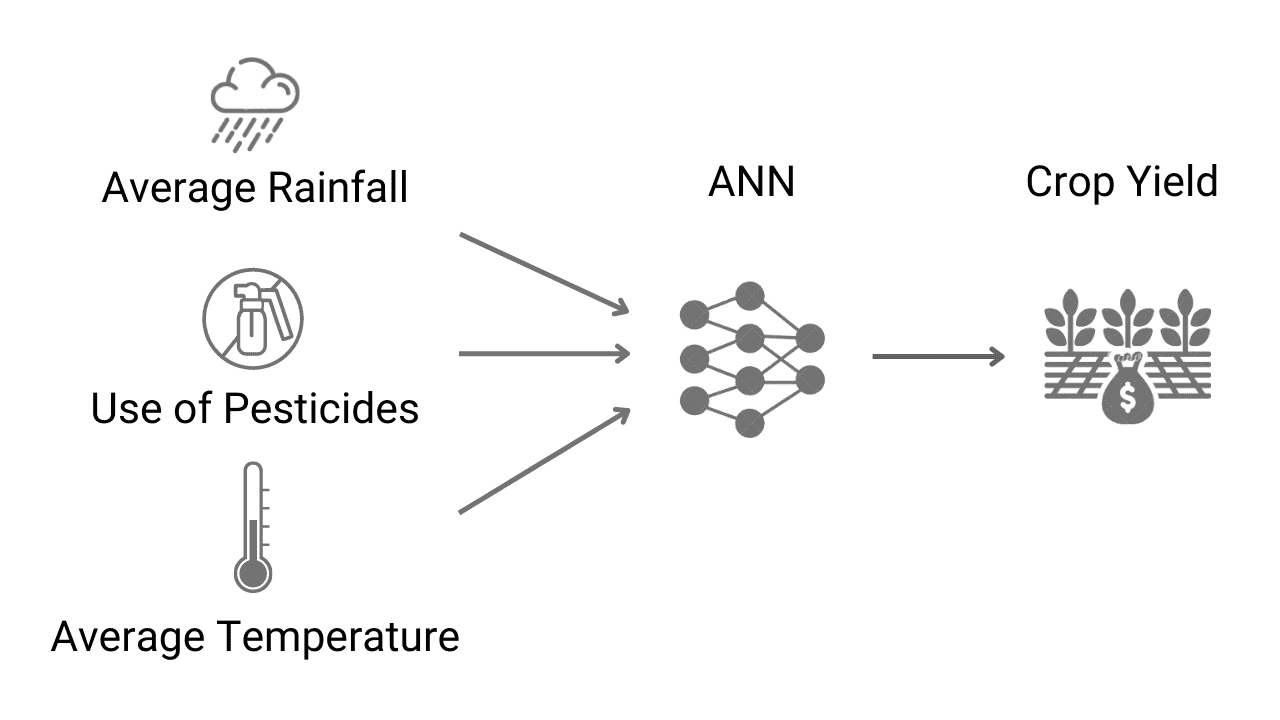
Crop Yield Prediction Using Machine Learning (ANN)
©2023 Code Algorithms Pvt. Ltd.
All rights reserved.