Courses
Courses
Blogs
Blogs
Tags
Reviews
Stories
Contact Us
EnjoyMathematics
system-design-concepts
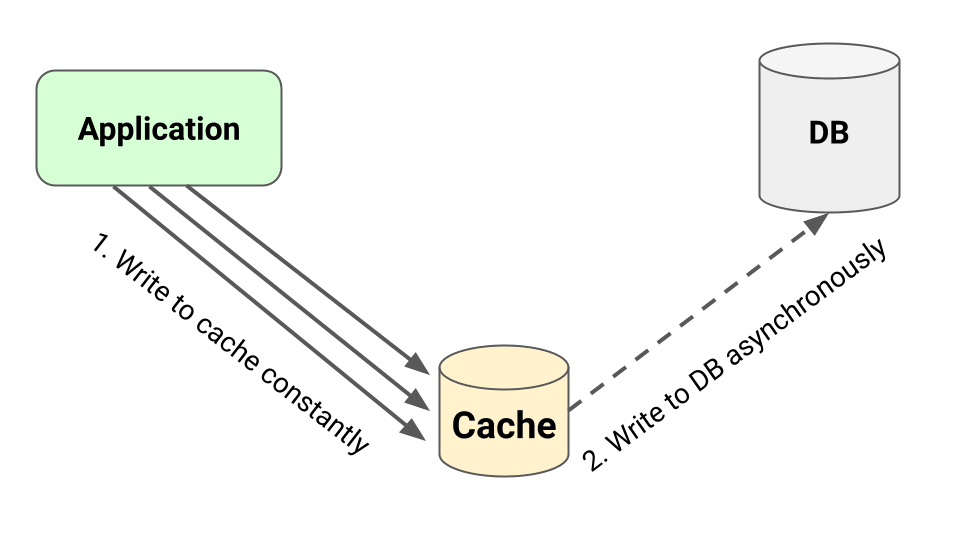
Caching Strategy: Write-Behind (Write-Back) Pattern
03 August 2023
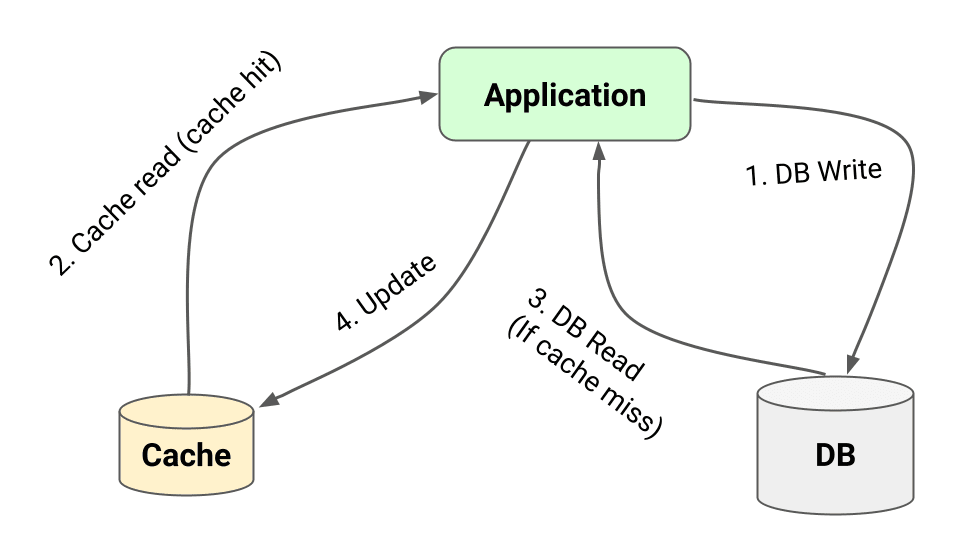
Caching Strategy: Write-Around Pattern
02 August 2023
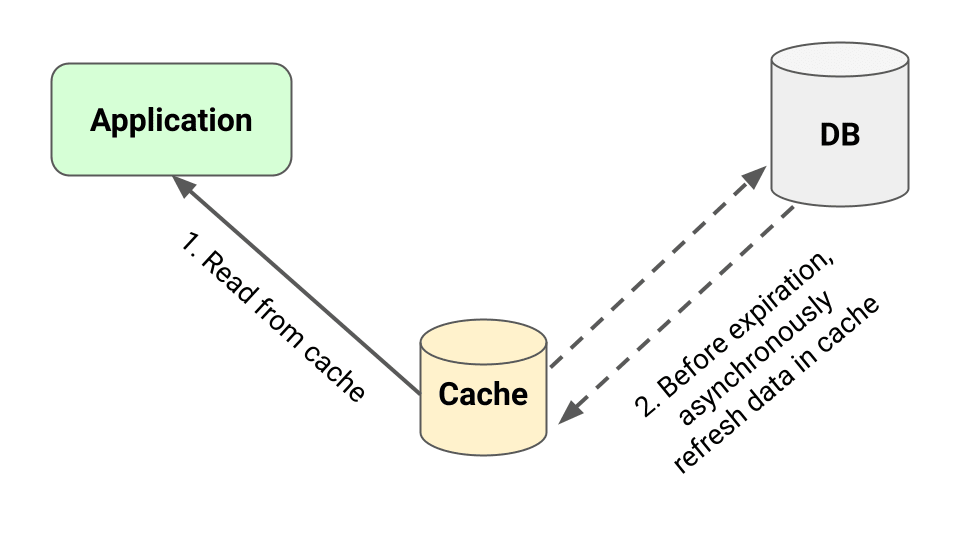
Caching Strategy: Refresh Ahead Pattern
02 August 2023
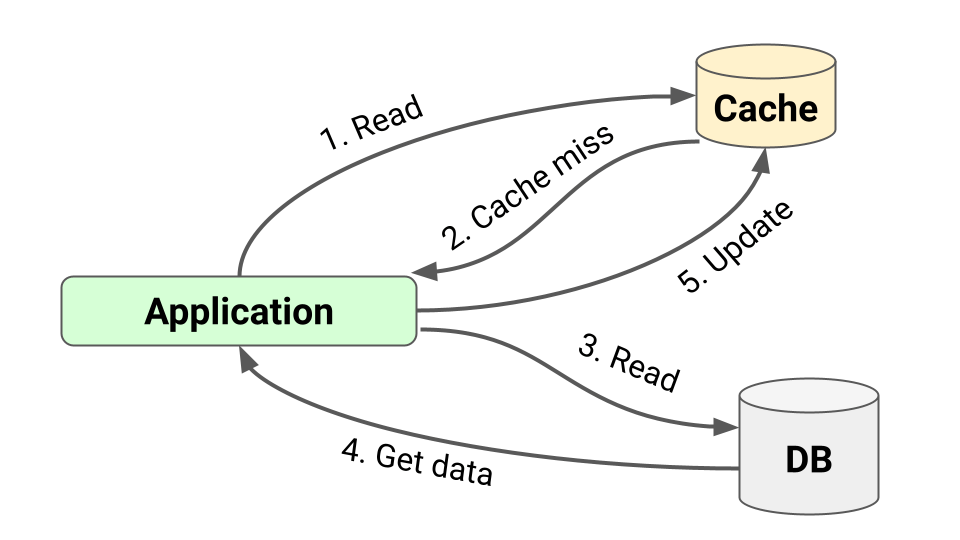
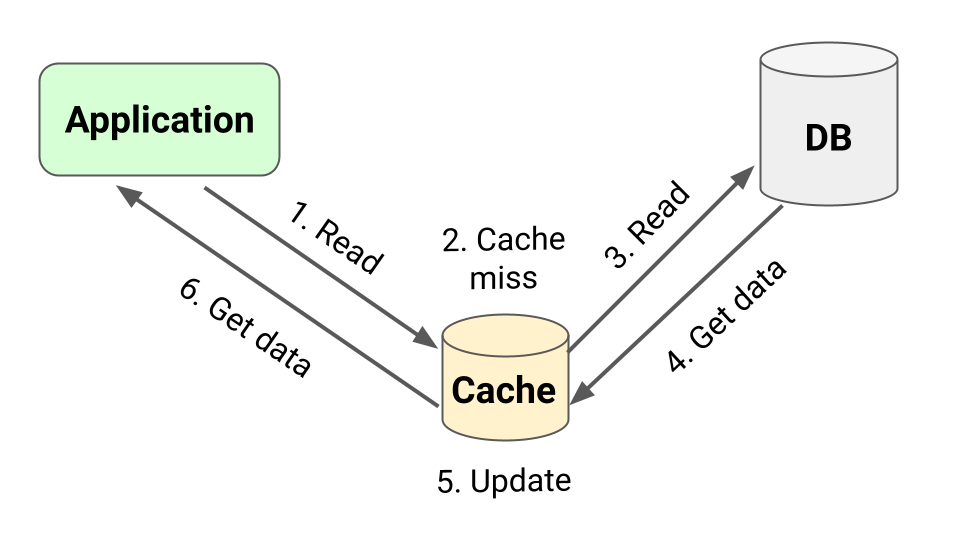
Caching Strategy: Cache-Aside Pattern
25 July 2023
Caching Strategy: Read-Through Pattern
25 July 2023
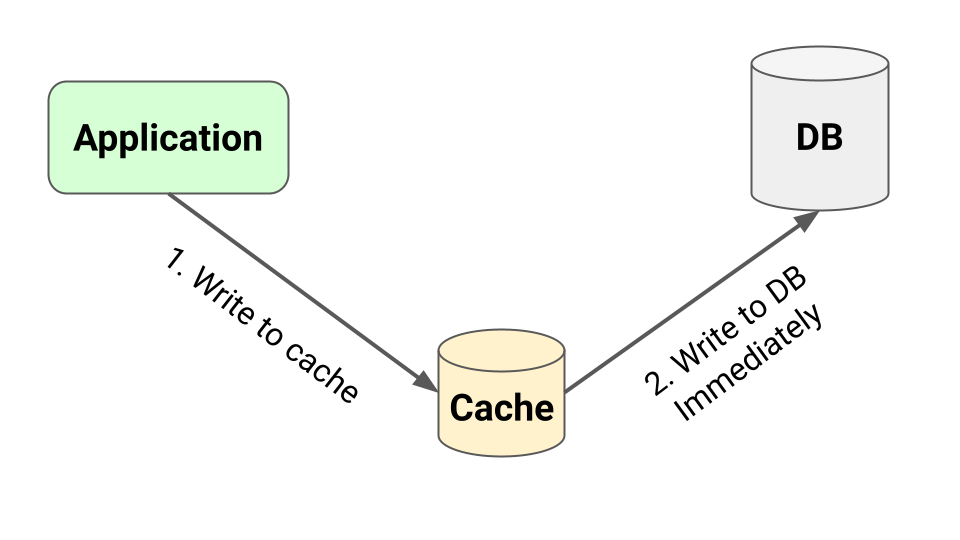
Caching Strategy: Write-Through Pattern
25 July 2023
Load More Blogs
Find us on:
Linkedin
Medium
Facebook
Twitter
Courses
Latest Blogs
Shubham Blogs
Ravish Blogs
Popular Tags
EnjoyMathematics
About Us
Contact Us
Terms and Conditions
Refund Policy
Privacy Policy
Cookie Policy
©2023 Code Algorithms Pvt. Ltd.
All rights reserved.