
machine-learning
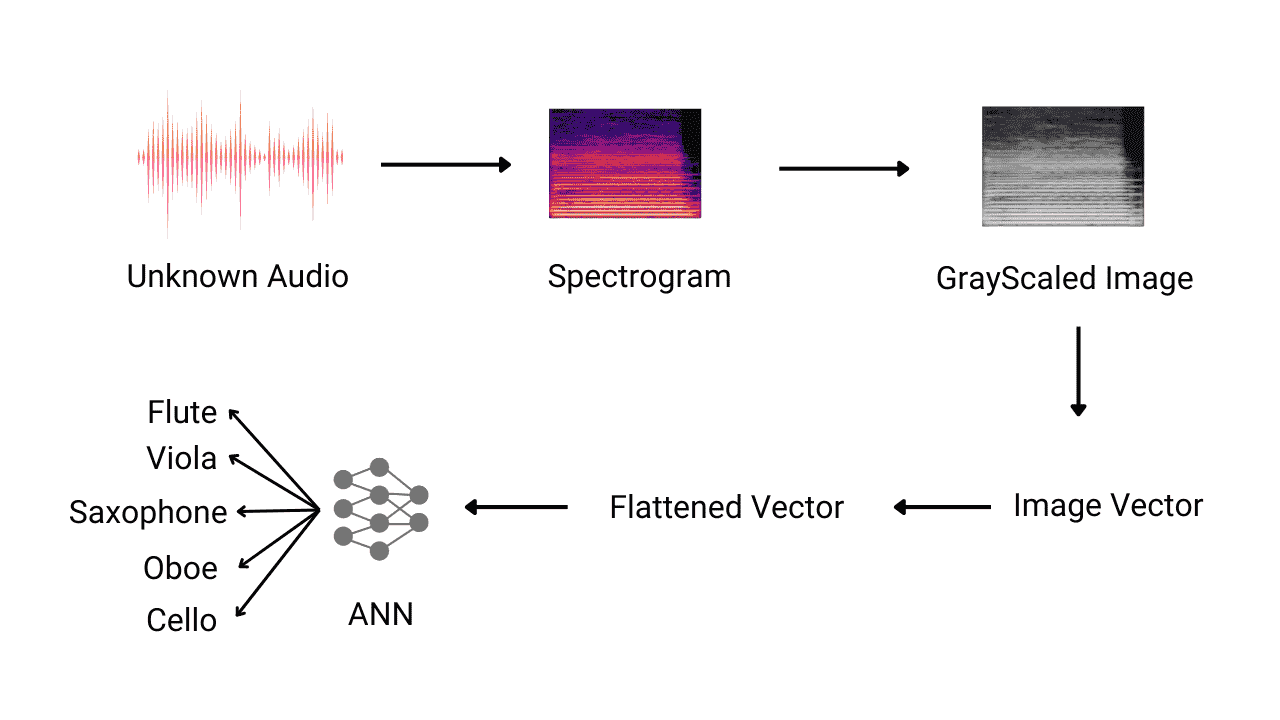
Detection of Music Instrument using Neural Networks
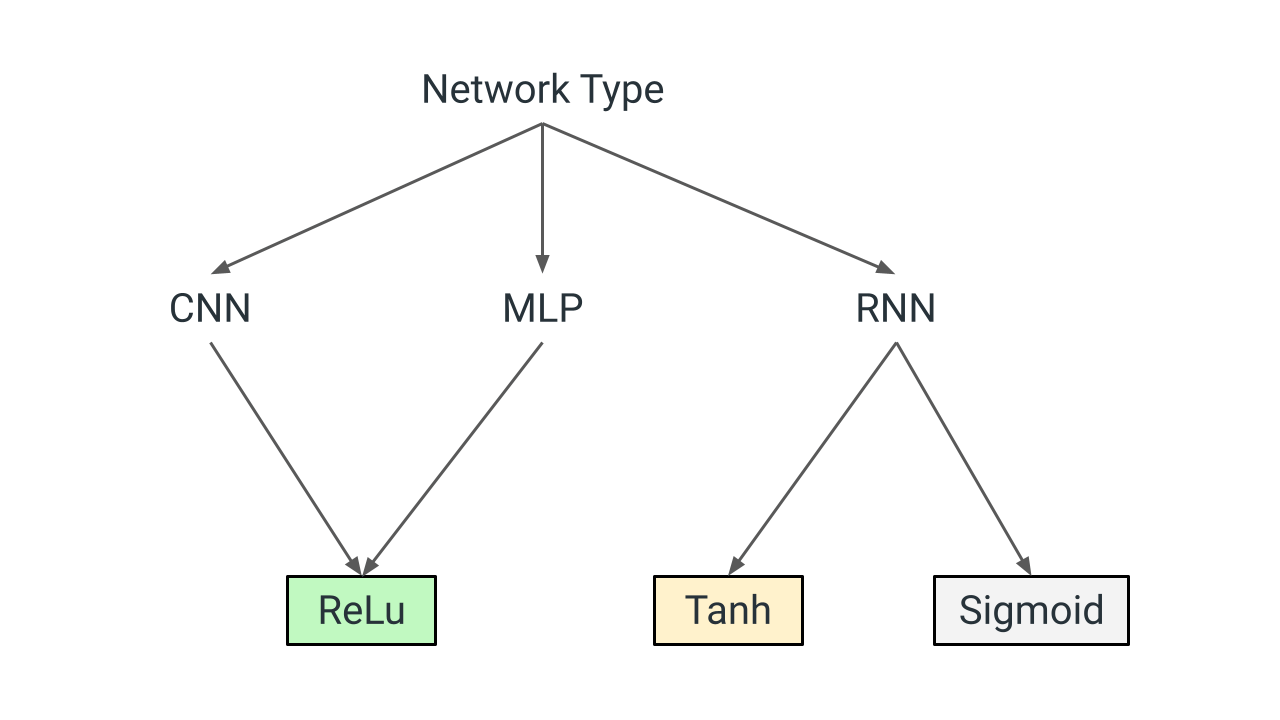
Activation Function for Hidden Layers in Neural Networks
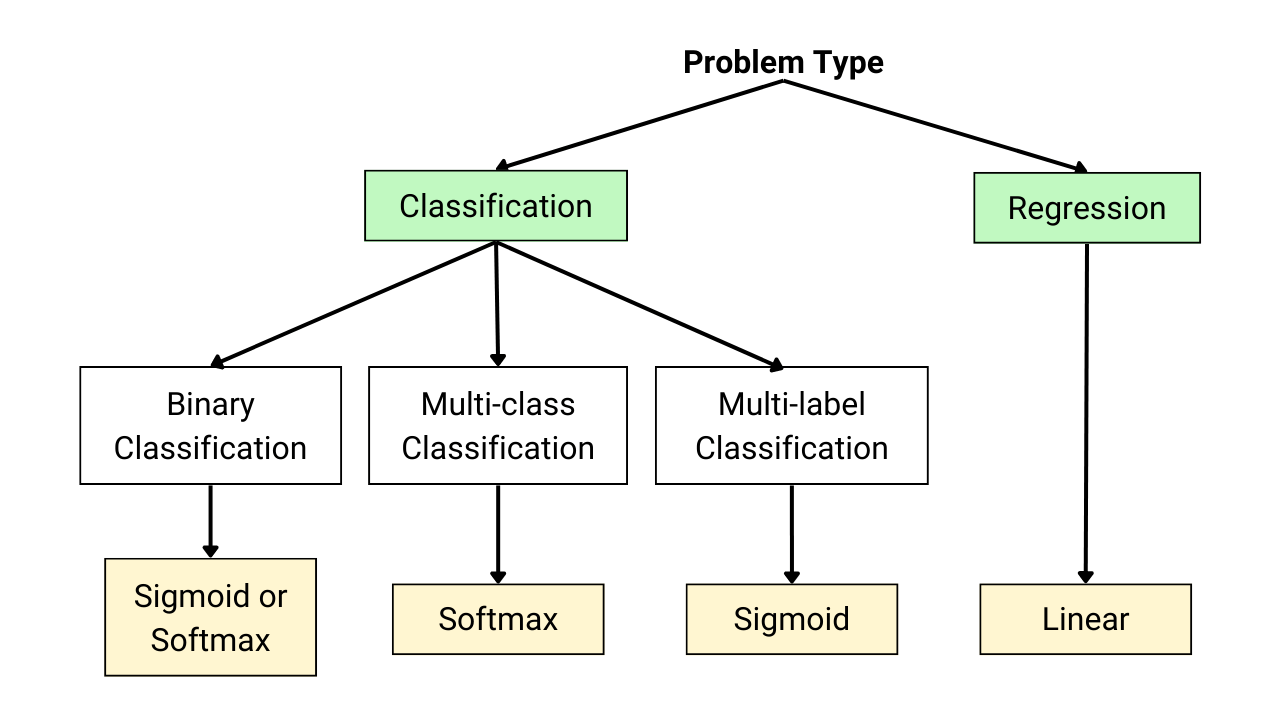
Activation Functions for Output Layer in Neural Networks

What is Big Data? Types, Characteristics and Examples
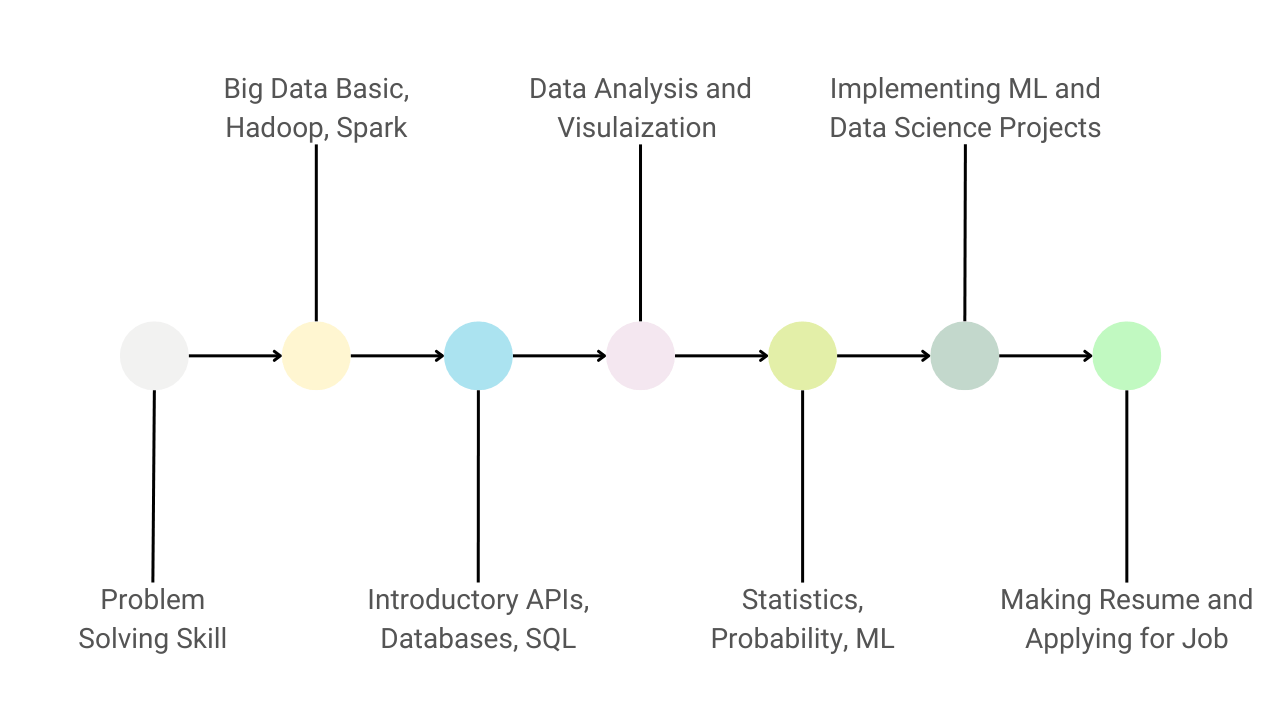
Guide to Learn Data Science and Become a Data Scientist
Stock Market Price Prediction Using Machine Learning
©2023 Code Algorithms Pvt. Ltd.
All rights reserved.