
Database Partitioning in System Design
What is data partitioning?
Database partitioning is the backbone of distributed database management systems. It is a process of dividing a large dataset into several small partitions placed on different machines. In other words, It is a way of partitioning data like index-organized tables into smaller pieces so that data can be easily accessed.
- It distributes data across several partitions to improve availability, scalability, and query processing performance. The combined data from all partitions is the same as the data from the original database.
- The partition architecture is transparent to the client application, where the client application keeps talking to the database partitions as if it was talking to a single database.

What are the problems solved by database partitioning?
With the growth in services and user base, it becomes tricky for a single database server to function efficiently. We may experience lower performance with the architecture of a single database server. Here is some situation that could arise:
- Database operations become slower.
- Network bandwidth starts reaching the saturation level.
- The database server starts running out of disk space at some point.
Database partition helps us fix all the above challenges by distributing data across several partitions. Each partition may reside on the same machine (coresident) or different machines (remote). The idea of co-resident partitioning is to reduce individual indexes size, and the amount of I/O needed to update records. Similarly, the concept of remote partitioning is to increase the bandwidth access to data by having more RAM, avoiding disk access, or having more network interfaces and disk I/O channels available.
A high level view of partitioned tables
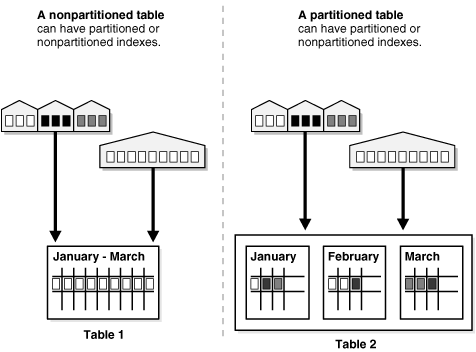
When to partition a table?
There are several scenarios when partitioning data can be beneficial:
- When data is too large to fit in the existing database.
- When database indexes grow continuously, it will impact the query performance. So one can partition the database and distribute the data across multiple partitions. This will improve query performance by reducing the amount of data that needs to be accessed for each query.
- When new data is added on a daily basis like a table containing historical data where only the current month's data is updated and the other 11 months' data are read-only. In other words, when historical data is queried less frequently than recent data, we can use partitioning to separate older data into different partitions. This will improve query performance because now queries can be targeted to specific partitions based on the time range.
- When there is a need to distribute data across different storage devices to improve scalability and parallelism (executing queries in parallel across multiple partitions).
- When there is a need to handle specific data access patterns. For example, one can partition data based on customer segments, geographical regions, or product categories to optimize data retrieval.
However, not all cases require data partitioning. So it is important to carefully analyse the specific needs of the system before deciding whether or not to use partitioning.
Why do we need data partitioning?
- By partitioning the database, we can ensure high availability. Here individual partitions can be managed independently, so if one partition becomes unavailable, the other partitions can still execute database queries. This will avoid a single point of failure for the entire dataset.
- Keeping data in different partitions helps the database administrator do backup and recovery operations on each partition, independent of the other partitions. This could allow the active partition to be made available sooner so access to the system can continue while the inactive data is still being restored.
- As traffic increases, the performance of the service can decrease. So data partitioning helps us to scale out the service and remove any limitations on scalability.
- We can improve security by storing sensitive and non-sensitive data in different partitions.
- As discussed above, It will improve performance because instead of querying the entire database, now system can query smaller partitions.
- Data partitioning divides tables and indexes into smaller, more manageable units. So this "divide and conquer" approach of data management helps us simplify the maintenance of particular table partitions.
Data Partitioning Methods
There are various data partitioning strategies. Let’s have a look at each one of them.
Horizontal Partitioning or Database Sharding
Horizontal partitioning (also known as database sharding) is a strategy for splitting table data horizontally based on the range of values defined by a partition key. Here we divide the table into smaller and more manageable tables, with each row of the table being assigned to one of the partitions.
- The partition key is responsible for distributing the data among all the partitions. When a query is made using the partition key, the database will determine which partition it needs to query.
- We need to balance the number of requests between partitions to ensure that none become overloaded.
Suppose there is a large database containing multiple rows of customer data that has a slow query performance. So we can think of partitioning the table into two separate tables horizontally. The first table would contain the first half of the customer data, and the second table would contain the second half. Now query will go to either partition 1 or partition 2, depending on the partition key. For example, suppose we store the contact details for customers. In that case, we can keep the contact info starting with the name A-H on one partition and contact info starting with the name I-Z on another partition.
The benefit of the horizontal partition: The horizontal partitioning is the most fundamental partitioning method. It divides the database into separate partitions that have the same schema as the original database. So this makes it easy to answer queries without having to combine data from multiple partitions.
The disadvantage of the horizontal partition: Data may not be evenly distributed across the partitions. For example, if there are many more customers with names that fall in the range of A-H than in the range I-Z, the first partition may experience a much heavier load than the second partition.
Vertical Partitioning
Vertical partitioning (also known as normalization) divides a table into smaller tables based on columns. For example, in a social media application like LinkedIn, a user's profile data, list of connections, and articles they have written can be placed on separate partitions using vertical partitioning i.e. first partition for user profile data, second partition for the list of connections and third partition for the articles.
- Vertical partitioning can store different types of data in separate partitions. This can be useful when some data is more critical or sensitive than other data. For example, we could store passwords, salary information, and other sensitive data in a separate partition to provide additional security controls.
- Vertical partitioning can be a great help when our data is stored on a solid-state drive (SSD). The idea is: If certain columns are not frequently queried, we can partition the table vertically and move those less frequently used columns to a different location. This can help to reduce the I/O and performance costs associated with fetching frequently accessed items.
- Overall, vertical partitioning helps us separate slow-moving data from more dynamic data. Slow-moving data is a good candidate for caching in memory.
There are a few disadvantages to using vertical partitioning:
- It may be necessary to combine data from multiple partitions to answer a query, which can increase the operational complexity. For example, if a profile view request requires data from a user's profile, connections, and articles, this data will need to be retrieved from separate partitions and combined.
- If the website experiences additional growth, it may be necessary to further partition a database across multiple servers. This can be time-consuming and may require additional resources.
The choice of which type of partitioning to use depends on the structure of the data. In some cases, it may be useful to combine both horizontal and vertical partitioning. For example, if we have a large dataset of customer information with different data types, we could use vertical partitioning to divide the database and horizontal partitioning to divide the customer information.
Data Partitioning Criteria
There are a large number of criteria available for data partitioning. Most of them use partition keys to identify partitions. Some of the popular criteria are range-partitioning, list-partitioning, hash partitioning, etc.
Range Based Partitioning
In range partitioning, data is organized into partitions based on ranges of values of the partition key i.e. each partition contains rows with values for the partition key within a specific range. The ranges are typically contiguous and do not overlap, where each range specify a lower and upper bound for the partition. Any partition key equal to or higher than the upper bound of the range are added to the next higher partition.
Range partitioning is used in a few specific cases:
- When there is a need to organize data based on date and time. For example, a table with a date column as the partition key might have a January-2022 partition that contains rows with partition key values from 01-Jan-2022 to 31-Jan-2022.
- When data is regularly added to the database and there is a need to remove old data. By dividing the partitions into date ranges, it becomes easier to remove old data. For example, we could delete all rows relating to employees who stopped working for the company before 1991. This can be more efficient for a table with many rows than running a delete query to remove employee data <= 1990.
Hash-Based Partitioning
In hash partitioning, rows are divided into different partitions based on a hashing algorithm. This is different from range partitioning, which groups database rows based on continuous indexes.
Hash partitioning can be used in a few different ways:
- We can use a client request's IP address or application ID as an input to a hash function to generate a hash value. This value determines which database partition to use for the request. For example, if we have 4 database partitions and each request contains an application ID, we could perform a modulo operation on the application ID with 4 and take the remainder to determine the partition to use.
- Hash partitioning is a good method for distributing data evenly across partitions.
- It is an easy-to-use alternative to range partitioning, especially when the partitioning data is not historical or does not have an obvious partition key.
One disadvantage of hash partitioning is that it can be expensive to dynamically add or remove database servers. For example, if we want to add more partitions, we may need to remap some of the keys and migrate them to a new partition, which requires changing the hash function. During this process, a large number of requests may not be served, resulting in downtime until the migration is complete. We can solve this problem using consistent hashing!
List Based Partitioning
In list partitioning, each partition is defined and selected based on a list of values for a particular column, rather than a set of contiguous ranges. Some key points:
- The partition key can only consist of a single table column.
- It is easy to group and organize unrelated data sets in different partitions.
- We can partition data based on a specific column like region column, to ensure that data for each region is stored in a single partition. For example, we could store all customers from India in one partition and customers from other countries in different partitions.
As an example, consider a table with data for 20 video stores distributed among 4 regions:
- Region: India, ID Numbers: 3, 5, 6, 9, 17
- Region: USA, ID Numbers: 1, 2, 10, 11, 19, 20
- Region: Japan, ID Numbers: 4, 12, 13, 14, 18
- Region: UK, ID Numbers: 7, 8, 15, 16
Using list partitioning, we could partition the table so that rows belonging to the same region are stored in the same partition. This will help us to easily add or drop records relating to specific regions from the table.

Composite Partitioning
Composite partitioning is a method of partitioning data based on two or more partitioning techniques. In this method, data is first partitioned using one technique, and then each partition is further divided into sub-partitions using the same or a different method. Here all sub-partitions of a given partition together represent a logical subset of the data.
Composite partitioning can be a useful for organizing and managing large datasets. It can help to improve the performance and scalability of the database by providing more precise control over data placement.
There are several types of composite partitioning:
Composite Range-Range Partitioning: This method performs range partitioning based on two table entries. For example, we could first partition the data by date and then sub-partition the range by price.
Composite Range-Hash Partitioning: This method first partitions the data using range partitioning and then sub-partitions it using hash partitioning within each range partition.
Composite Range-List Partitioning: This method first partitions the data using range partitioning and then sub-partitions it using list partitioning within each range partition.
Composite List-Range Partitioning: This method performs range sub-partitioning within a list partition. For example, first perform list partitioning by country name and then perform range sub-partitioning by date.
Composite List-Hash Partitioning: This method sub-partitions list-partitioned data using the hash partitioning technique.
Composite List-List Partitioning: This method performs list partitioning based on two table dimensions. For example, perform list partitioning by country name and list sub-partitioning by customer account status.

Effective Data Partitioning Design
- Query Processing: Effective data partitioning strategies can enhance query performance by using smaller datasets and leveraging parallelism. In addition to that, partitioning simplifies backup and recovery processes by focusing on smaller components rather than the entire database.
- Application Considerations: Data partitioning's effectiveness heavily relies on specific requirements. While it can enhance availability, scalability, and performance, it introduces complexity to service design. So it's crucial to analyse data access, querying, and modification patterns to select the optimal partitioning approach.
- Rebalancing Partitions: With increasing system traffic, services may experience disproportionate loads. Consequently, there might be a need to redefine partitioning strategies and migrate data from old partitions to new ones to maintain balance.
Conclusion
Data Partitioning is the backbone of modern distributed data management systems. Data Partitioning proves very effective in improving the availability, scalability, and performance of the system. In this blog, we tried to present a full conceptual understanding of Data Partitioning. Hope you liked it. Please share your views in the comments below.
References
- https://docs.microsoft.com/en-us/azure/architecture/best-practices/data-partitioning
- https://docs.oracle.com/cd/B28359_01/server.111/b32024/partition.htm
- https://dev.mysql.com/doc/mysql-partitioning-excerpt/5.7/en/partitioning.html
- Book: Designing Data-Intensive Applications
Enjoy learning, Enjoy system design!