
XG-Boost (Extreme Gradient Boosting) Algorithm in ML
Boosting algorithms are leading the machine learning community in terms of popularity. And when we talk about the XGBoost, it is the most used algorithm to solve and win the Kaggle competitions. In 2015, Kaggle announced 29 winning solutions, and out of these, 17 used XGBoost. From this, we can sense the popularity of this algorithm, and hence it becomes essential to know about it. In this article, we will learn about XG-Boost in greater detail.
Key takeaways from this blog
After going through this blog, we will be able to answer the following questions:
- Evolution of tree algorithms.
- What is XGBoost, and why is it so popular?
- What are the features supported by XGBoost?
- Installation of XGBoost.
- Should we use XG-Boost all the time?
- Hyper-parameters involved in XG-Boost.
- Possible interview questions on XG-Boost.
So let's start our discussion with our first topic, which is:
Evolution Of Tree Algorithms
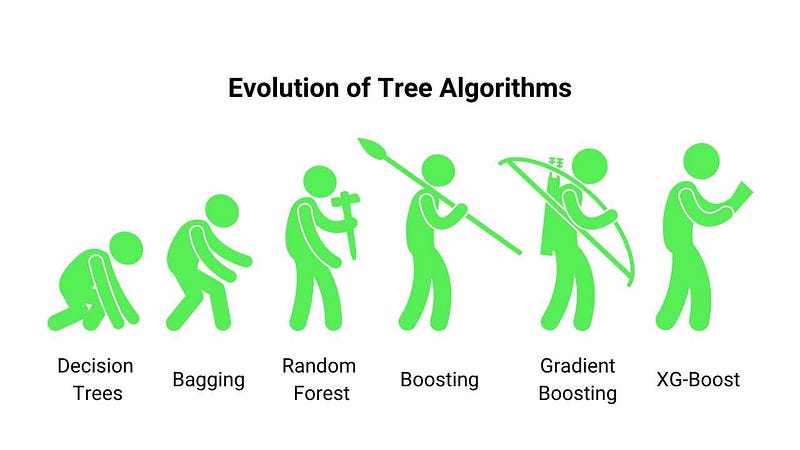
Artificial neural networks and deep learning lead the market for unstructured data like images, audio, and texts. At the same time, when we talk about small or medium-level structured data, tree-based algorithms dominate the market. And when we say tree, it all starts with the basic building block, i.e., Decision Trees. DTs were able to solve both classification and regression problems but suffered from the overfitting issues quickly. To tackle this, we ensembled multiple DTs with slight modifications in data formation. It created Bagging and Random Forest algorithms.
After that, researchers thought that ensembling trees randomly was time-consuming and computationally inefficient. Why not build trees sequentially and improve over those parts where previous trees failed. That's where boosting came into the picture. Later these boosting algorithms started utilizing the gradient descent algorithm to form trees sequentially and minimize the error in predictions; hence these algorithms are called Gradient Boosting. Later, researchers proposed model, algorithmic, and hardware optimizations to further improve the Gradient boosting algorithms' performance. The combination of all these optimizations over Gradient boosting is known as XG-Bo ost, and we will be discussing them in this article.
What is XGBoost?
XGBoost, also known as Extreme Gradient Boosting, is a supervised learning technique that uses an ensemble approach based on the Gradient boosting algorithm. It is a scalable end-to-end tree boosting system, widely used by data scientists to achieve state-of-the-art results on many machine learning challenges. It can solve both classification and regression problems and achieve better results with minimal effort.
The initial version of this algorithm was implemented using the Gradient Boosting machines. Later after making this work an open-source, a large community of data scientists started contributing to the XGBoost projects and improved this algorithm further. With the help of such a great community, XGBoost has become a software library and can directly be installed into our systems. It supports various interfaces, including Python, R, C++, Julia, and Java. So let's first install this library and then learn what features it does provide.
Installation of XGBoost
There is official documentation as an installation guide for XGBoost on the XGBoost installation guide. For XGboost in python, Python Package Introduction (PyPI) is the best to start. We can install XGBoost using pip as:
sudo pip3 install xgboostWe know that installing an additional package is always an overhead thing and decreases popularity until it provides something great. It's the same as getting the payment option on WhatsApp; it will be more convenient than using an additional Google Pay application until google pay provides some advanced features. Still, XG-Boost manages to give us something exciting, and people do not hesitate to install a different package. So let's see what features it does provide.
Features supported by XG-Boost.
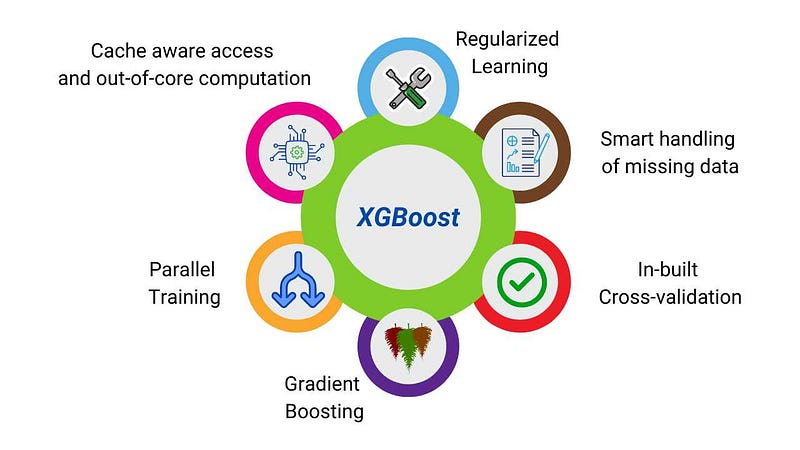
There are multiple supports that XG_Boost provides us. These supports are growing over time as this framework is open-source, and people contribute continuously to enhance the features. Some of the most prominent features are:
Model Support
- Regularized learning: Overfitting is always a concern for stronger algorithms, and to solve this, XG-Boost penalizes the overfitting tree using both L1 and L2 regularization techniques.
- Gradient Tree Boosting: XG-Boost supports the primary Gradient boosting algorithm known as Gradient Boosting Machines (GBM).
- Shrinkage and Column Subsampling: We scale the learnings made newer trees by some factor. This shrinkage reduces each individual tree's influence and gives new trees a chance to improve the model's performance. Apart from shrinkage, it also supports column and row subsampling on the dataset to form the GBM. This column subsampling is the same as used in the Random Forest algorithm.
Split Finding Algorithms' Support
- Weighted Quantile Sketch: XG-Boost authors proposed a distributed weighted quantile sketch algorithm to automatically find the best splitting points in weighted datasets. The general idea was to propose a data structure that supports merge and pruning operations, with each operation proven to maintain a certain accuracy level. Details of this algorithm can be found in the research paper appendix section.
- Sparsity-aware split finding: Nowadays, it is quite probable that the data received is sparse because of multiple factors, including missing values in the data, frequent zero entries in the statistics, and artifacts of feature engineering such as one-hot encoding. XG-Boost treats sparsity as a missing value and learns the best direction to handle them. According to the experimentation, this addition improved the performance by 50x compared to the basic implementation.
System Design Support
- Column Block for Parallel Learning: XG-Boost uses parallelization for growing the trees sequentially. The most time-consuming part of the tree learning algorithm is getting the data in a sorted manner. To do this efficiently, XG-Boost proposed in-memory units, called blocks, to store the data. While building the base learners, we use nested loops where the outer loop corresponds to enumerating a tree's leaf nodes, and the inner loop calculates the features. These loops are not interchangeable in the base implementation, creating overhead in computation. Using column blocks, XG-Boost made this loop interchangeable and created a scope of parallelized learning.
- Cache-aware Access: XG-Boost authors' designed a cache-aware prefetching algorithm that changes read/write dependency to a longer dependency and helps to reduce the runtime overhead when the number of rows in the data is significant. They allocate an internal buffer in each thread, fetch the gradient statistics into it, and then perform accumulation in a mini-batch manner.
- Blocks for Out-of-core computation: To handle the big data that does not fit into the memory of our systems, XG-Boost uses out-of-core computation by dividing the dataset into multiple blocks and storing these blocks into disks.
Evolved Supports
- In-built cross-validation method: XG-Boost now comes with an in-built cross-validation method using which it can automatically search and specify the number of hosting iterations required.
- Continued Training: An already trained XG-Boost model can be further tuned on a newer dataset.
These features and supports are growing continuously as the XG-Boost library is open source, and a large group of developers is contributing here. Looking into the details of this algorithm, we might be wondering, why other algorithms then? So let's understand this.
Should we always use XG-Boost if this is so effective?
Indeed, XG-Boost's support is exciting and widely configurable, yet we can not say that it will always work best. There is nothing like one algorithm for all kinds of solutions in Machine Learning. It is always advisable to try out different algorithms and then decide which works best per our requirements. Sometimes accuracy is not the sole requirement that we expect from our machine learning model. We also want a decent amount of explainability, lesser computational complexity, and ease in deployment. These factors also help in selecting the best model for our requirements.
Before ending our discussion, let's understand one important thing, i.e., what are the hyperparameters involved in this algorithm that can be tuned to extract the best out of it.
Hyperparameters involved in the XG-Boost algorithm
To learn any machine learning algorithm, we must know the different factors that can affect the performance of our model when we try to fit that algorithm into our dataset. In XG-Boost, these factors are:
- n_estimators: Number of trees we want to grow sequentially.
- max_depth: Maximum depth allowed for a tree.
- learning_rate: Slow learners are said to be better learners, and to control the updation step in residuals, we need to tune the learning rate.
- subsample: To control the factor of row sampling.
- colsamplebytree, colsamplebylevel: To control the factor of column sampling.
In addition to these, XG-Boost provides the functionality where we can define the grid of values (multiple values of these parameters in arrays), and the in-built cross-validation technique will find the best set of parameters.
Possible interview questions on XG-Boost
XG-Boost provides great support and is very popular in the industry. So if there are some projects in our resume that uses this algorithm, then some most probable questions that can be asked o this topic are:
- What's the difference between XG-Boost and normal Gradient Boosting machines?
- What additional supports XG-Boost provide?
- What is an ensemble approach, and how is XG-Boost an ensemble approach?
- What are the different hyper-parameters involved in XG-Boost?
- Did you try to verify XG-Boost's accuracy/efficiency difference compared to other trees/non-tree algorithms?
Conclusion
Here, we learned about the most famous algorithm to solve machine learning challenges over different competitive platforms, i.e., XG-Boost. We list down all the supports it provides to improve the performance over the standard tree algorithms. We also discussed the different hyperparameters to tune the performance of XG-Boost further. We hope you enjoyed the article.
Enjoy Learning! Enjoy Algorithms!
Share Your Insights
More from EnjoyAlgorithms
Self-paced Courses and Blogs
Coding Interview
OOP Concepts
Our Newsletter
Subscribe to get well designed content on data structure and algorithms, machine learning, system design, object orientd programming and math.
©2023 Code Algorithms Pvt. Ltd.
All rights reserved.