
Feature Engineering for Machine Learning (Tools and Techniques)
While training Machine Learning models, data availability is one of the biggest bottlenecks. Even if the data is present, it misses essential attributes that can help models learn better. Also, attributes in their native state are not scaled, making models biased towards particular features.
To resolve such hurdles, feature engineering is the technique that allows us to generate or rectify existing features to enhance our model's performance. This blog will teach us more about feature engineering and its various techniques.
Key takeaways from this blog
- What is Feature Engineering?
- Why is Feature Engineering so important?
- Benefits of Feature Engineering
- Steps in Feature Engineering
- Feature Engineering Techniques
- Feature Engineering Tools
Let's start with our first question.
What is Feature Engineering?
Features are like food to machine learning models. Like we process our food before eating them, we must process features before feeding them into the model. Feature engineering is one such pre-processing step performed while developing machine learning models. Here we extract meaningful features from available raw data, which helps increase model performance drastically.
Feature engineering has become more critical with the recent "Data-based" machine learning trend. Let's take one example: Suppose we have raw features like 'Current' and 'Voltage' values for any lithium-ion batteries, but the model expects 'Power' to predict the battery's charge percentage. But we do not have a 'Power' feature. Here comes the need for feature engineering, where we transform the existing features so that it becomes helpful for the ML model. We can form a new feature by multiplying the 'Current' and 'Voltage' values, which will result in 'Power'.
Initially, feature engineering was a manual task, consuming significant time. But since 2016, the entire feature engineering process can be automated, which helps us extract meaningful features from raw data. There are four main processes involved in feature engineering :
- Feature Creation,
- Feature Transformations,
- Feature Extraction and
- Feature Selection.
Let's discuss each one of them one by one.
Feature Creation
A dataset contains hundreds and thousands of attributes, but not all are suitable for building a Machine Learning model. We sometimes need to create features from the existing features and then use that particular attribute for training the model. There can be multiple ways to do so, but some common methods include the following:
- Feature Construction: We sometimes need to combine available attributes after performing operations on raw data. We saw an example of this case where we combined Voltage and Current features to make a new Power feature. This requires the domain understanding in which we are applying ML.
- Feature Extraction: We sometimes need to perform averaging or extrapolating a single feature to make it suitable for our requirements. For example, we can have the data of atmospheric temperature recorded every second, but only hourly data is needed. So we will average the results for every 3600 samples to find the temperature for that hour.
Developers sometimes need to design their strategy to develop a new feature to enhance the ML model's performance.
Feature Transformation
Raw data has multiple attributes, and every feature has its defined range. For example, the engine temperature recorded for a car will range from 20°C to 100°C, while the car's speed will range from 0 KMPH to 200 KMPH, and the distance covered can be in the range of 5000 Km to 7000 Km. If we directly use these features while building the model, our model will become biased towards the distance features as the magnitude of distance is very high.
So we adjust the feature variable to improve the machine learning model's performance by making it unbiased towards any particular feature. A prevalent example would be scaling all features within a specific range (e.g., 0 to 1). Standardization and Normalization are some perfect techniques for the same, and we will study the details of these methods in our "Why we need scaling?" blog.
Feature Extraction
It involves extracting new features from the raw data. This is different from feature creation as here, we mainly want to reduce the total number of features used to build the ML model but, at the same time, retain the maximum information from the earlier data.
As discussed in feature creation, we took the average temperature and lost data for every second. But in feature extraction, we ensure that the intermediate information is least hampered. This helps a lot while modelling data and visualizing the features. Some popular feature extraction methods are PCA, t-SNE, cluster analysis, and edge detection, and details of these algorithms can be found on our Machine Learning course page.
Feature Selection
It is a way of selecting the subset of the most relevant features from the original features by removing the redundant, noisy, or irrelevant ones. Features can suffer from missing values/null values, garbage values, constant values, noisy values, too many outliers and many more. These anomalies can drastically reduce our ML model's performance, which is shown in the image below.
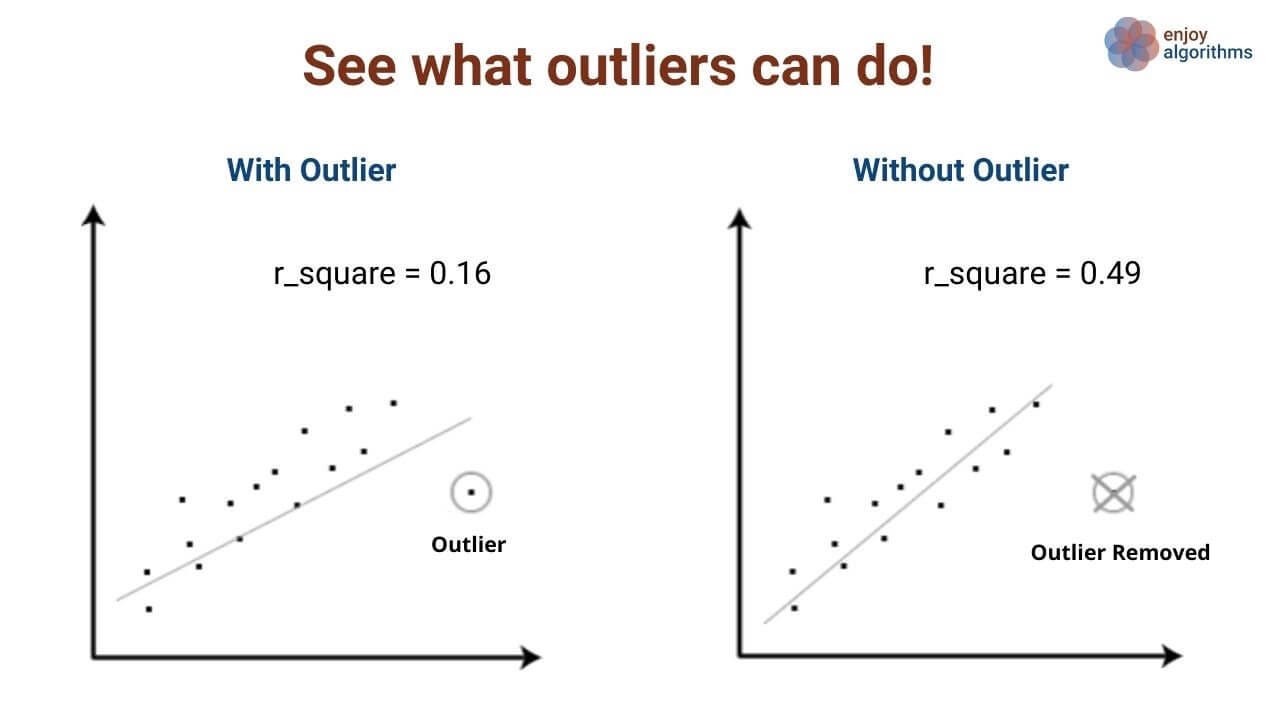
If a feature is essential but is of deficient quality, we must remove it from our final feature list as it will negatively affect the performance. Hence we do feature selection techniques to create a subset of features from the existing attributes and then use it for training ML models. This process needs knowledge about the domain we are applying Machine Learning.
For example, to predict the remaining useful life of the battery, we have recorded the atmospheric temperature values as a feature which does not affect battery life. So we can drop this feature which is influenced by our domain knowledge that atmospheric temperature does not affect battery health.
Why is Feature Engineering so important?
Machine learning workflow involves several steps, each with its own time set. Below pie chart shows the time distribution in each step involved and is based on the survey conducted by Forbes.
Data scientists invest around 80% time in the pre-processing step. This is where feature engineering helps and provides the most relevant features for model training. We can learn more about pre-processing of structured data in this blog.
But why can't we train our model on raw features? Why is data pre-processing required? Why don't we have the features needed in a table and use them directly?
We can not train a Machine Learning model on raw features because:
- Multiple organizations are collecting data, and we can not wholly rely on the information that they have open-sourced. Also, many of these datasets come from sensors that can quickly become faulty or noisy. Hence we need to check the data quality before training an ML model.
- Data normalization or standardization is required to make our model unbiased towards any specific feature. To check the biases, we do the sensitivity test on our model, where we change specific features very minutely and check the prediction of our model. Our model is highly biased or sensitive to that feature if it differs drastically.
- We need to perform Feature extraction and selection on the raw data, which may contain irrelevant, redundant, or noisy features and can negatively impact model performance.
- We sometimes need to convert the existing features into numerical forms so that machines can understand them. For example, in the case of categorical or textual data, we need to perform vector encoding and then feed it to the corresponding ML model.
- Sometimes data suffers from class imbalance. It is a scenario where one class dominates another class or class. For example, in spam and non-spam email classification, we have 5000 samples of spam emails but 500 samples of non-spam emails. The model will become biased towards spam class and start predicting spam for all emails. Hence we need to perform balancing in the classes.
In summary, data pre-processing is an essential step in machine learning to ensure high performance for ML models.
Benefits of Feature Engineering
The most common benefits of feature engineering while building a model are as follows:
- Higher efficiency of the model: The model will be able to process more samples per second. The higher the number of features, the more computation time will be required by the model, which will make prediction slow. After feature engineering, there will be fewer or more meaningful features, and the model will become efficient.
- Greater flexibility of the features: The changes in essential features will be more noticeable by the ML models rather than influenced by features that do not contribute too much. For example, the atmospheric temperature was not contributing to predicting the battery's remaining life. We can drop this feature and make the model more focused on features deriving the battery's life.
- Faster Training: It will be easier for models to learn from meaningful data and be trained faster. A higher number of features will require more learnable parameters, making training slow.
- Simple Algorithms can fit the data: In the case of raw data, we were biased towards heavier ML algorithms, but with feature engineering, even simple algorithms can find the hidden patterns in data.
What are the various steps in Feature Engineering?
Steps involved in feature engineering vary from person to person and model to model. But some common steps are required, and they are:
- Data Preparation: This is the essential step that makes our raw data in a suitable format for our model. It can involve cleaning of data, data augmentation, loading, etc.
- Exploratory Analysis: It is an approach to analyze the data using statistical graphs and other visualization methods. With the help of various visualization techniques, data scientists select the most appropriate feature to train the model. One can learn the detailed methods present in EDA in this blog.
- Benchmark: Benchmarking sets a standard baseline for performance and then compares which features can help us achieve or beat that target. A benchmark model is a reference model against which we measure our model's accuracy. It helps us to improve the prediction and select the best set of features.
Cleaning up raw, unstructured, and dirty data bulks may seem daunting, but various feature engineering techniques help us. Let's learn more about it in the next section.
What are the Techniques used in Feature Engineering?
Feature engineering techniques that are used very frequently are:
Imputation
Human errors and data flow interruptions can lead to missing values in data. These need to be handled to prevent having an impact on the performance of the model. There are two types of imputation:
-
Numerical Imputation: Numerical features can have missing values for some records. For example, missing some values in a list that contains the count of the number of people eating a particular product in a region. These missing values can be filled by the median, average, or just the number 0. An example is shown below:
data_imputed = data.fillna(0) ## We fill all missing values with 0. ## Do note that it assumes that all missing data here is numerical -
Categorical Imputation: When the feature is categorical, and it contains missing values, we can replace them with the majority categorical value for that column. A new field called 'Other' can also be created, which is helpful if there is no most frequent categorical value or if replacing missing values with the most frequent ones leads to an increase in outliers.
data_imputated['categorical_column_name'] = data['categorical_column_name'].fillna(data['categorical_column_name'].value_counts().idxmax()) # #here missing values of categrical column are filled by their max value
Please note that we can use 'inplace=True' to update in the same data frame. This is a feature of Pandas. For more details, you can refer to the blog.
Handling Outliers
Outlier handling techniques help us to remove outliers and help to increase the performance of models. The improvement is drastic for models like linear regression, which are susceptible to outliers. The various methods are:
- Removal: We can remove all records containing outliers. This method is only feasible when the number of Outliers is manageable (Please note that each outlier is considered on a single column and not as a combination of them).
- Replacing values: Here, outliers are handled with a suitable imputation, like missing values.
- Discretization: Here, we convert a set of continuous variables to discrete ones. The most common method is creating bins/ groups, i.e., all values in that group are given a single value.
We can use the Standard deviation for identifying outliers because identification is the most difficult part of working with datasets having outliers. For example, a point larger than a particular distance within a space can be considered an outlier.
One-hot encoding
This is the most basic type of encoding used to give a numerical value to categorical features. We all know models play with numbers, and this encoding helps assign a unique vector for each feature. It works when the number of features is finite, and the vector length corresponds to the number of features. An example is shown below.
# Total features are 4
Men = [1,0,0,0]
Women = [0,1,0,0]
Child = [0,0,1,0]
Girl = [0,0,0,1]Log Transform
It is also known as logarithm transformation. When we have skewed distributed data, we want to turn it into less skewed or normally distributed data. We can transform this feature by taking the log of that and using the resulting values. An example is shown below:
data_log_transformed['log' + '_column_name'] = np.log(data['column_name'])Scaling Features
Feature scaling is an essential step in data pre-processing. The features can be scaled up or down as per needs and can improve the performance of many algorithms, especially distance-based algorithms like K-Means. The commonly used methods are :
- Normalization: All values present in a feature are scaled between a definite range (commonly used are 0 and 1). A widespread example is a min-max normalization. After Normalization, features become closer to each other, especially if feature values vary greatly; hence, outliers need to be removed before Normalization.
- Standardization: It is also known as z-score Normalization, where we perform the mean centering and make standard deviation 1. It becomes helpful when applying a gradient descent algorithm in Machine learning.
More details about the feature scaling can be found in this blog.
One can refer to the data pre-processing hands on the blog for more detailed techniques on feature engineering.
There are also some tools to make applying feature engineering a lot easier. Let's discuss some of these tools to conclude our discussion.
Feature Engineering Tools
These tools help us to do the whole feature engineering and produce relevant features efficiently for our models. Some of the standard tools are:
Featuretools
It is an open-source library used to perform automated feature engineering. Data Scientists use it to fast-forward the feature generation process and develop a more accurate model.
TsFresh
It is available as a Python package and helpful when features are related to time series. We can also use it along with the feature tools. It helps us extract features like the number of peaks, maximum value, etc., to train our model.
Interview Questions
- What is the main aim of feature engineering?
- What are the steps of feature engineering?
- Why is feature engineering considered difficult?
- Can we use PCA for feature selection?
- Name some benefits of feature selection.
Conclusion
Feature engineering is an essential method that extracts critical features from the available features in the dataset. It can drastically improve our model's performance, making it necessary to understand. This blog discussed the basics of feature engineering and the various steps involved. We hope you enjoyed reading the article.
If you have any queries/doubts/feedback, please write us at contact@enjoyalgorithms.com. Enjoy machine learning!