
How Machine Learns in Machine Learning?
In Machine Learning, a machine learns by using algorithms and statistical models to identify patterns in data. Here process of learning begins with feeding a large amount of training data to the algorithm. The algorithm then uses this data to make predictions or take actions based on the patterns it has identified.
In other words, the algorithm constantly adjust its parameters to minimize the difference between its predictions and actual outcomes. Over time, it continues to learn from the training data and update its parameters. As a result of this, algorithm becomes better at making accurate predictions and solve the problem.
Problem Statement
Let's understand the above idea via an example. Suppose there are two points in a coordinate plane represented by (X1, Y1) and (X2, Y2). Our goal is to determine the value of Y for a given value of X, such that the point (X, Y) lies on the line that passes through the two given points.

Let's start by using a traditional programming approach to solve this problem. The equation of a straight line is Y = mX + c, where m represents the slope or gradient and c represents the intercept. It is important to note that there is only one unique line that can pass through any two given points (X1, Y1) and (X2, Y2).

In traditional programming, functions produce corresponding outputs based on the given inputs. To solve this problem, we define the parameters of the straight line (slope and intercept) and function linear_function(X), which takes the X coordinate as input and returns the corresponding Y coordinate that lies on the line represented by Y = mX + c.
# (X1, Y1) Coordinates of first point
# (X2, Y2) Coordinates of second point
slope = (Y2-Y1)/(X2-X1) #X2 != X1
intercept = (X2*Y1 - X1*Y2)/(X2-X1)
def linear_function(X):
Y = slope*X + intercept
return YWith this approach, traditional programs will find the exact equation of the line. The image below shows a computer where we are writing our functional program and giving it some input. Based on that input, it predicts the output.

Now, let's move on to understanding how Machine Learning solves this problem. Before that, let's define the term regression problem. In regression problems, Machine Learning algorithms are designed to learn how to predict continuous outputs.
To solve the linear regression problem, we can represent the relationship between any input and output data as Y = WX + B, where W and B are weight and bias matrices, respectively. The dimensions of these matrices depend on the type of problem being solved. With this analogy, we can formulate the problem we discussed earlier as Y = WX + B, where W is equal to the slope or gradient (m) and B is the intercept (c).
In traditional programming, we use gradient and intercept formula for straight lines to calculate the values of m and c, and pass input data into the linearfunction to produce the output. For a machine learning approach, we need a set of input and output data that the machine can use to learn a mapping function from input to output. In simpler terms, Machine Learning will try to learn the **linearfunction**.
As we know, the linear_function requires the values of m and c, which are the slope and intercept, respectively. In Machine Learning, the machine will automatically find these variables based on the input and output data provided to it in the form of a dataset.

So, let’s quickly form the dataset using which ML algorithms will try to find m and c.

The equation of the line, Y = X + 1 fits the given dataset. This means that the slope (m) is 1 and the intercept (c) is 1. You might be wondering why we need Machine Learning if we already know the output values. To understand this, consider the analogy with learning in school.
Just like we use practice examples to learn theory, and then test that learning in exercises or exams, the initial datasets (training datasets) in Machine Learning serve the same purpose. These datasets provide the input and output values for the machine to learn from. Once the machine has learned from these examples, it can then generate output for any given X as input.

Let’s go through the steps that the machine will follow to find the values of slope and intercept
Step 1: The machine starts by selecting random values for the slope (m) and the intercept (c), for example m = 0.1 and c = 0.5. Then, it uses these values to find the predicted output (Ŷ) for the input from the training dataset.
Step 2: The machine then calculates the difference between the predicted output (Ŷ) and the actual output (Y) from the training dataset. This difference is known as the error, which can be measured using various methods such as Mean Square Error (MSE), Mean Absolute Error (MAE), Root Mean Square Error (RMSE), etc. The goal is to minimize this error for better predictions.

Mean Square Error (MSE) is a cost function in machine learning, which measures how well the model is able to fit the training data, and the goal of training is to minimize this error. By minimizing the MSE, we can ensure that the machine learning model is making accurate predictions.
Step 3: There are two parameters based on which MAE varies, i.e., values of slope(m) and intercept( c ). So the above equation of cost function is a function of m and c. MAE = f(m, c). To better visualize this, we can represent three dimensions with slope (m), the intercept (c), and the cost as the three axes. When the machine randomly selects values for m and c in step 1, it starts at some position A. Now it's goal is to reach position B, where the cost function is at its minimum value. In other words, our aim is to find the values of m and c that minimize the cost function (equivalent to minimizing the error function).
Step 4: Now machine will update the value of m and c such that the cost function will decrease from the previous value. It does this by using optimization algorithms like gradient descent, which calculates the gradient of the cost function with respect to m and c and updates their values accordingly.
Step 5: Now process of updating m and c values and re-calculating the cost function based on the new value of Ŷ will repeatedly iterate until it reaches the point (or nearest to the point) B, where the cost function is minimum. After reaching point B, the value of m and c will be the learned parameters for the machine. Now, whenever someone gives any finite value of X to our machine learning model, it will predict the value of Y corresponding to every X.
Overall, machine tried learning the Weight (W) and Bias (B) matrices. This is one special case where both the matrices are constituted of single elements, i.e., m and c. In the case where W and B will have dimensions >1, ML algorithms will try to learn every element that constitutes the weight and bias matrices for that particular data. In the figure below, a11, a12 ….. is the (m X n) matrix elements, and ML will try to learn the value of a11, a12, …., amn.
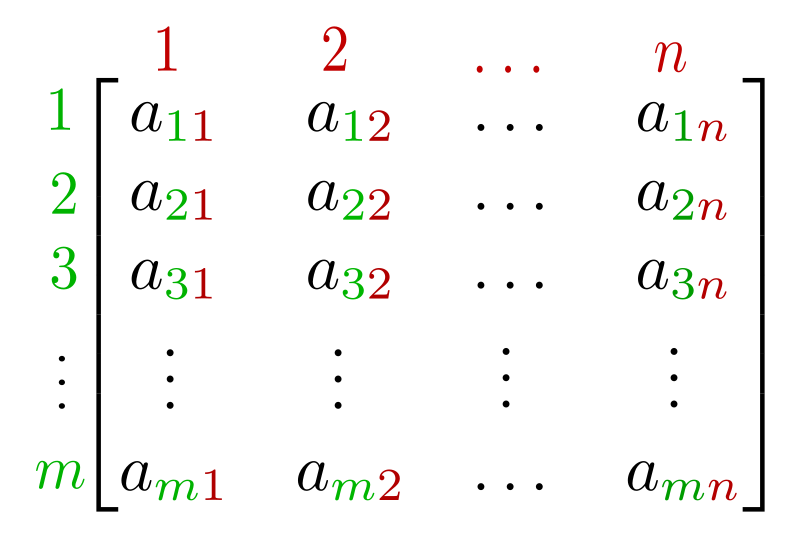
So we have explained the process by which the machine actually learns, and this capability of learning is known as Machine Learning.
Critical questions to explore
- What are weight and bias matrices?
- What other options are available in place of MAE?
- Isn’t it a lengthy process where ML algorithms tweak the value of m and c in every iteration? Can this process be faster? (Hint: Optimisers).
- What if no one perfect line could fit all the data?
Conclusion
In this article, we have discussed how machines actually learn in the field of Machine Learning. We addressed a common problem of finding the value of a straight line using two methods: a traditional programming approach and a machine learning approach. Enjoy Learning, Enjoy Algorithms!
Share Your Insights
More from EnjoyAlgorithms
Self-paced Courses and Blogs
Coding Interview
OOP Concepts
Our Newsletter
Subscribe to get well designed content on data structure and algorithms, machine learning, system design, object orientd programming and math.
©2023 Code Algorithms Pvt. Ltd.
All rights reserved.