
Supervised, Unsupervised and Semi-supervised Learning with Real-life Usecase
In our previous article (here), we discussed classifying machine learning models on five bases. We learnt that ML models can be classified into four major categories based on the nature of the input data we provide to the machine learning algorithms. These four categories are:
- Supervised Learning
- Unsupervised Learning
- Semi-Supervised Learning
- Reinforcement Learning
In this article, we will discuss these categories in more detail.
Key questions that are being answered in this blog
- What are Supervised, unsupervised, semi-supervised, and Reinforcement Learning? How are they related to each other?
- Why are these terms named “Supervised” and “Unsupervised”?
- How are classification, regression, or clustering algorithms linked with supervised and unsupervised Learning?
- What are the famous algorithms associated with supervised or unsupervised approaches? Why are most real-life scenarios more likely to be related to semi-supervised Learning?
Let’s start and dive deeper into these categories without any further delay.
Supervised Learning
Supervised Learning is a category in which we feed labelled data as input to the machine learning model.

Here input and output values are already known, and the machine learning algorithm learns the mapping function from input to output. Mathematically, for Y as the Output and X as the input, machine learning algorithms try to find the best mapping function f such that Y = f(X). If you observe closely, Learning happens like some supervisor supervises the learning process. We already know the answers, so the algorithm tries to map the function so that the predicted output must be close to the actual output.
Let’s say the machine has learned a mapping function f predicting values Y’ for every X passed as an input to the function. Once the difference between predicted (Y’) and actual (Y) goes below a certain threshold (in simple terms, errors become negligible), learning stops.
Supervised Learning can be further categorized as follows:
1. Classification: Taking the example of the following image, images of shapes are the input to the machine learning model, and labels of those images as shape names are the output data. The labelling process is called “annotation”. Based on these input and output data, the model learns to predict the category of unseen image data, whether a rectangle, circle, triangle, or hexagon.

2. Regression: Example of the following image shows experience (in years) on the X-axis. For every experience, there is one salary (per month Rupees) on the Y-axis. Green dots are the Input and Output data coordinates (X, Y). So regression problem tries to find the continuous mapping function from input to output variables, for example, the blue line in the image. If the order of the mapping function is fixed to 1, which is a linear function, the model will learn the blue line shown in the image.

Some famous use cases of Supervised Learning are:
- Object detection and Image classification: Find whether a cat is present in the image or not. If yes, then find the location of the cat in that image.
- Recommendation systems: If someone has bought a new home, automatically suggest new furniture as most people bought them together.
- Time series prediction: If the last three days’ atmosphere temperature of India was 21°C, 22°C, and 21°C, then what would be the temperature for tomorrow?
Some frequently used algorithms in Supervised Learning
- Linear Regression and Logistic Regression
- SVM (Support Vector Machines)
- Random Forest
Unsupervised Learning
Unsupervised Learning is a category of machine learning in which we only have the input data to feed to the model but no corresponding output data.

Here, we know the value of input data, but the output and mapping functions are both unknown. In such scenarios, machine learning algorithms map the function that finds similarity among different input data instances (samples) and groups them based on the similarity index, the output for unsupervised Learning. We can say that algorithms generate a pseudo output for learning the mapping function.
In such Learning, there is no supervision as there is no existence of output data. Hence they are called Unsupervised Learning. Algorithms try to find similarity between different input data instances by themselves using a defined similarity index. One of the similarity indexes can be the distance between two data samples to sense whether they are close or far.
Unsupervised Learning can further be categorized as:
1. Clustering (Unsupervised classification): Using the example below, we have input data consisting of images of different shapes. Machine learning algorithms try to find the similarity among other images based on the colour pixel values, size, and shapes and form the groups as outputs in which similar input instances lie. If you notice, squares get clustered together, and similarly, circles and hexagons.

Clustering Algorithms are:
2. Dimensionality Reduction: When attributes of the data samples have more than three dimensions, there is no way to visualize the relationship among attributes, as we can not plot variables in more than 3 Dimensions. But without analyzing the input data, we can never be sure about the machine learning model’s performance. To solve this problem, we use dimensionality reduction techniques to reduce the total dimensions and analyze the data. Suppose we want to study 10 features together but cannot visualize the 10D plots. So, we try to reduce the dimensions to 3 or lower to easily plot it, analyze their relationship and do further processing.
Dimensionality Reduction Algorithms are:
3. Association: Such Learning is more about discovering rules that describe a large portion of the data. Customers who bought a banana also bought carrots, and customers who bought a new house also bought new furniture. At first, it will look similar to clustering, but clustering is about finding the relationship among data points, and association is about finding the relationship among attributes/features of those data points.
Example Association Algorithm is:
Some famous use cases of Unsupervised Learning are:
- Market segmentation: Whether the market is hot or cold is based on the money revolving in the market.
- Fraud detection: Categorize transactions into fraudulent and non-fraudulent groups.
- Image segmentation: Gray colour objects in an image taken from a car represents roads.
Some frequently used algorithms in Unsupervised Learning:
Semi-Supervised Learning
Semi-supervised Learning is a category of machine learning in which we have input data, and only some input data are labelled. In more technical terms, the data is partially annotated.

Semi-supervised Learning is partially supervised and partially unsupervised.
Let’s take one example from the below image to make it clear. Suppose a bucket consists of three fruits, apple, banana, and orange. Someone captured the image of all three but labelled only the orange and banana images. Here, the machine will first classify the new apple image as not a banana or orange. Then someone will observe these predictions and label them as apples. Then retraining the model with that label will allow it to classify apple images as an apple.
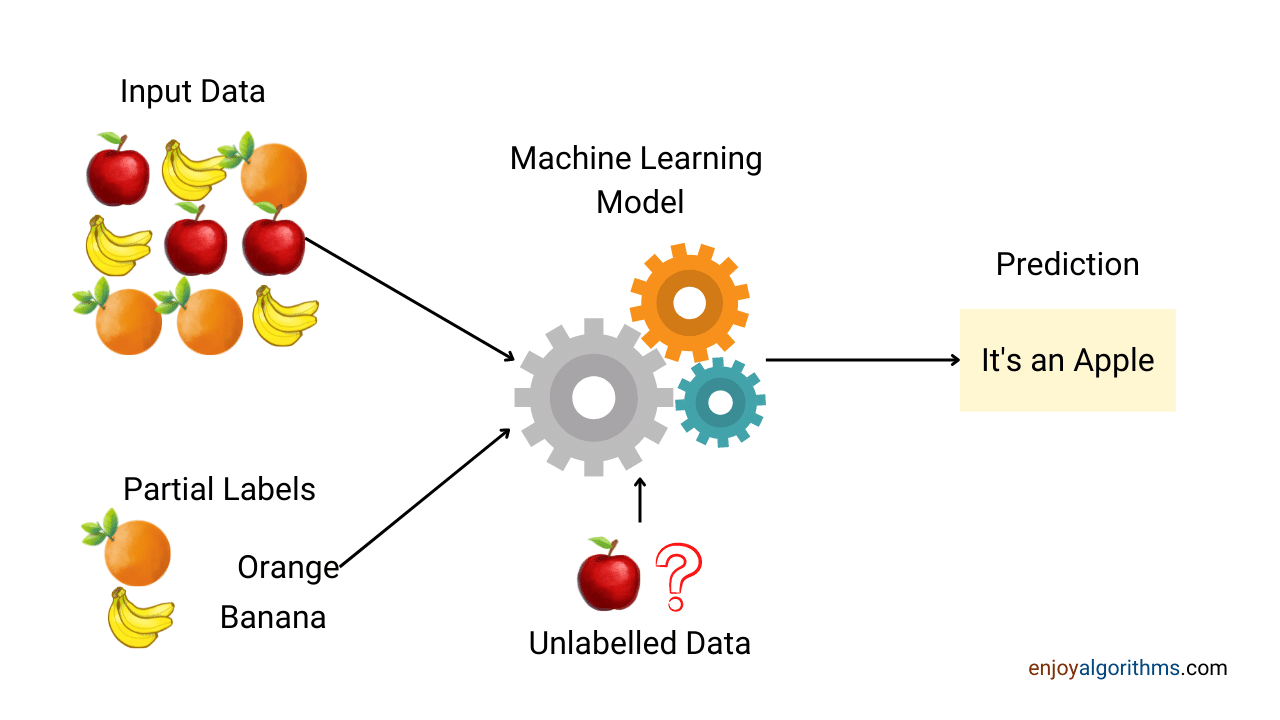
Nowadays, capturing a tremendous amount of data has become a trend. Many big companies have collected millions of Terabytes of data and are still collecting. But labelling collected data requires a workforce and resources, so it’s too expensive. This is the main reason that many real-life databases fall into this category.
Some famous use cases of Semi-supervised Learning are:
In such types of Learning, one can use either supervised Learning or unsupervised learning methods.
Supervised Learning: Train a model on labelled data and then use that Learning to predict output for unlabeled data. This output for the corresponding unlabeled input data can now be treated as the pseudo label. Now we can use partial and pseudo-labelled data to train another supervised learning model.

For example, suppose there is a large chunk of data in the image above, and a small amount of labelled dataset is present. We can train the model using that small amount of labelled data and then predict on the unlabelled dataset. Prediction on an unlabelled dataset will attach the label with every data sample with little accuracy, termed a Pseudo-labeled dataset. Now we can train a new model with a mixture of the true-labelled and pseudo-labelled datasets.
Unsupervised Learning: We can capture and learn the structure present in the data.
Reinforcement Learning
Here, Machine Learning algorithms act as virtual agents in the known environment where these agents choose the possible action options. The agent selects the best action from all the possibilities present in that environmental state and, based on that selection, receives reward/risks. The algorithms keep an eye on maximizing the reward, reducing the risk, and eventually learning.
Let’s take one example. Suppose we want our computer to learn “How to balance the pole on the moving cart”? We might have played this game in childhood, balancing sticks on our palms.

Here, the hand is replaced by a cart. Suppose we want to make our cart smart enough to balance the stick. So “cart” is the agent, the plane on which the cart will move is the environment, and the cart is taking possible actions such as moving either left or right to balance the stick. So, whenever a stick falls in either direction, the cart will act appropriately to make it stand. Suppose we told our agent that the longer it holds the stick upright, the higher the reward will be.
After every action, the state of the cart and the stick in the environment will change. Our agent will analyze that state and again take different actions best suitable for that particular state.

Some famous use cases of Reinforcement Learning are:
If we look at the history of machine learning, we will find that RL is quite old and has been in the industry for a more extended period. But because of the requirement of awareness of the entire environment states, it is usually used with simulated environments. Some of the most common use cases where it is being used in the industry are:
- The agent can drive the vehicle inside the simulated environment.
- Predicting the stock price in the stock market.
- Agents that can play games.
Some Frequently used algorithms in Reinforcement Learning :
- Q-Learning
- Deep Q-Learning (DQN)
Critical Questions to Explore
- Why do we name different machine learning algorithms as supervised or unsupervised Learning?
- Why is semi-supervised Learning the most common case in Machine Learning?
- How can we utilize semi-supervised Learning in case of object detection problems?
- Can we think of why supervised Learning can never bring the future we expect from Machine Learning?
- Why is the annotation process required?
Quick Note

Conclusion
This article described machine learning classification based on the “Nature of input data.” We came across the definition of Supervised, Unsupervised, Semi-Supervised, and Reinforcement Learning and discussed some industry use-case or real-life use-case of these categories. We also listed some famous algorithms associated with each category. We hope you have enjoyed the article.
Enjoy Learning, Enjoy Algorithms!
Share Your Insights
More from EnjoyAlgorithms
Self-paced Courses and Blogs
Coding Interview
OOP Concepts
Our Newsletter
Subscribe to get well designed content on data structure and algorithms, machine learning, system design, object orientd programming and math.
©2023 Code Algorithms Pvt. Ltd.
All rights reserved.